For a deeper dive, see our ChatGPT SEO guide.
ChatGPT Doesn't Have Rankings
Let's clear this up first: ChatGPT doesn't have rankings in the traditional sense.
When someone asks Google a question, they get 10 blue links. Position matters. When someone asks ChatGPT a question, they get one answer. Maybe it mentions 3-4 options. Maybe just one. There's no page 2 to scroll to.
So "ranking in ChatGPT" really means: getting mentioned at all, and getting mentioned favorably.

Watch: Why AI Won't Recommend Your Brand
How ChatGPT Decides What to Mention
ChatGPT decides what to include based on three core signals.
Recognition
Does ChatGPT know your brand exists? Can it correctly identify who you are?
If your brand name is a common word (like Copper, Honey, or Notion), ChatGPT might not associate it with your company at all. Test this: Ask ChatGPT "What is [your brand]?" with no context. If it gets confused or talks about something else, you have a recognition problem.
Entity clarity matters more than volume of content. Name your brand and core concepts in the intro and early headings. Use the exact phrases you want to be known for. Refer to those entities consistently instead of rotating synonyms. Several smaller brands have reported displacing higher-authority sites once they cleaned up how clearly and consistently they described themselves.
For more on this, see What is AI Brand Recognition.
Authority
Does ChatGPT trust your brand enough to recommend it?
Authority comes from: - Reviews on G2, Capterra, Trustpilot - Media coverage and press mentions - Third-party comparisons and "best of" lists - Backlinks and citations from authoritative sources
Brands with weak authority signals AI platforms recognize get left out even if ChatGPT recognizes them.
Relevance
Is your brand associated with the specific query?
ChatGPT needs to connect your brand to the user's question. If someone asks "best CRM for real estate agents" and your content never mentions real estate, you won't appear.
Relevance is built through use-case specific content, landing pages, and consistent messaging about who you're for.
Why Is My Brand Invisible When People Ask ChatGPT?
Your brand is invisible in ChatGPT when it fails one or more of the three signals: recognition, authority, or relevance. The most common cause is weak entity recognition. If ChatGPT doesn't confidently know your brand exists as a distinct entity in your category, it won't include you in recommendations regardless of your website quality.
Test this by asking ChatGPT "What is [your brand]?" in a fresh session. If the response is vague, wrong, or describes a different entity, you have a recognition problem. If it's correct but you still don't appear in category queries ("best [your category] tools"), you have a relevance or authority gap. See the recognition, authority, and relevance framework above for the specific fix for each signal.
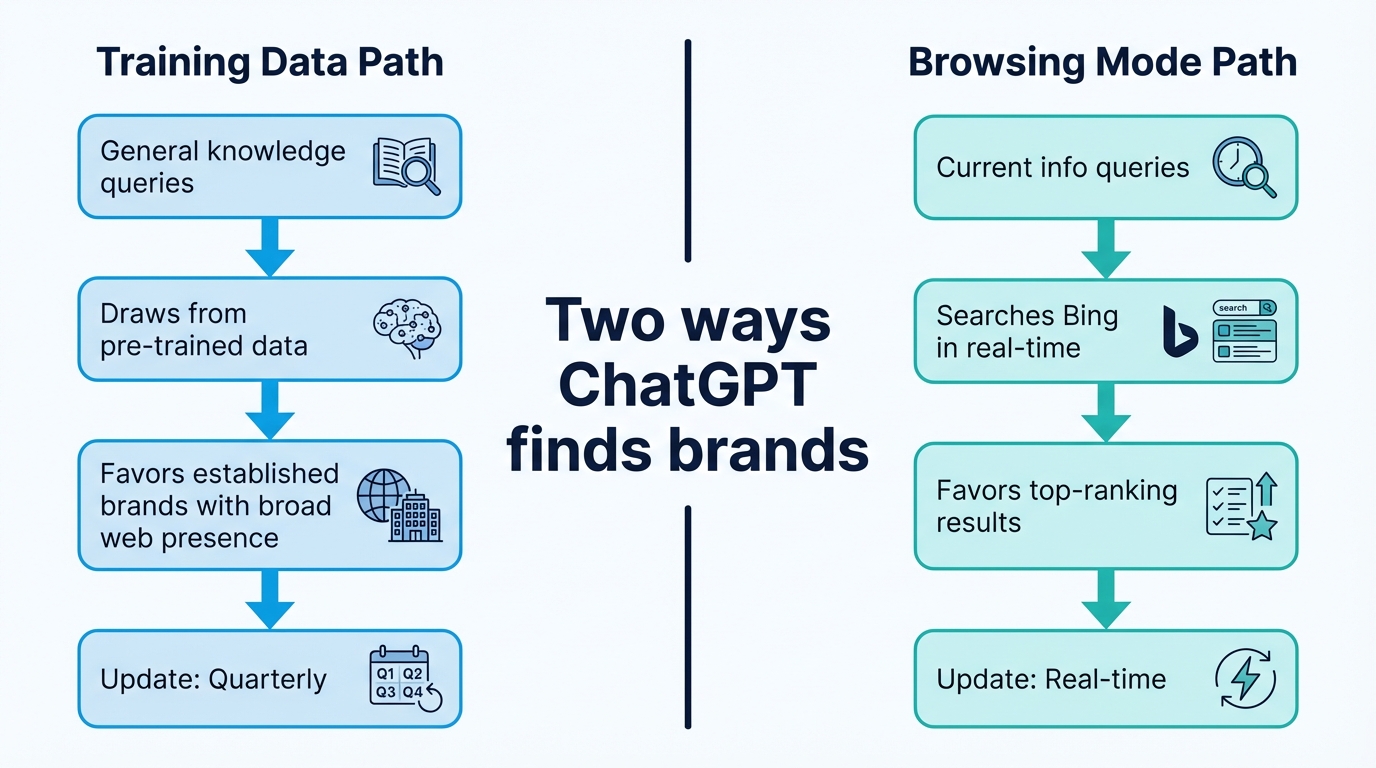
ChatGPT's Browsing Mode vs Training Data
ChatGPT uses two distinct pathways to generate responses, and optimizing for each requires different tactics.
| Dimension | Training Data Path | Browsing Mode Path |
|---|---|---|
| Trigger | Default for general knowledge queries | Activated for queries needing current information |
| Data freshness | Months to years old (depends on training cutoff) | Real-time web results via Bing |
| Optimization tactic | Build broad web presence, earn editorial coverage, collect reviews | Traditional Bing SEO, content freshness, crawlability |
| Best for | Established brands with existing web footprint | Newer brands, time-sensitive content, product updates |
The training data path is where most brand recommendations happen. When someone asks "what's the best CRM for startups?" without needing current pricing or features, ChatGPT draws from what it learned during training. This favors brands with large, consistent web presence across authoritative sources.
The browsing path kicks in when ChatGPT needs current information. It runs Bing searches, reads top results, and synthesizes an answer. This pathway favors traditional SEO signals: ranking well on Bing for relevant queries gives you a direct path into ChatGPT's browsing results.
Most brands need to optimize for both. Training data determines your baseline visibility. Browsing determines whether ChatGPT can find and recommend you for real-time queries.

Tactics for ChatGPT
Build Recognition Signals
- Claim review profiles: G2, Capterra, Trustpilot. These are heavily indexed.
- Ensure consistency: Same description everywhere. Same positioning. Same name.
- Earn Wikipedia presence: If you're notable enough, this carries significant weight.
- Get covered in media: TechCrunch, Forbes, industry publications.
Build Authority Signals
- Collect reviews: More reviews on more platforms = stronger signal.
- Create citable content: Original research, benchmarks, data studies. Include concrete stats with clear context and specific numbers. If a line feels like something you could point to in a slide or memo, it usually makes good citation material.
- Earn backlinks: From authoritative sites in your space.
- Get into comparison content: "Best X tools" lists, analyst reports.
Build Relevance Signals
- Target use-case queries: Create content for "[your category] for [specific use case]"
- Use exact language: If users search "CRM for small sales teams," use those exact words.
- Build category association: Consistently connect your brand to your category.
Write Content AI Can Extract
AI answer engines tend to reward clarity over narrative. McKinsey reports that brand-owned pages make up only 5-10% of sources AI uses, making every page count.
- One clear question or intent per page
- The answer at the very top (BLUF / TL;DR)
- Short factual paragraphs with clean H1 / H2 hierarchy
- Phrasing that matches how people type prompts
- FAQ pages using literal question phrasing
- Comparisons that line up clear options and criteria
Here are concrete before/after examples of what works:
Before: "Our platform provides comprehensive solutions for modern businesses looking to grow their online presence." After: "Acme CRM serves 12,000+ small businesses. Core features: pipeline management, email automation, and reporting. Integrates with Shopify, Stripe, and HubSpot." The second version gives ChatGPT specific, citable facts instead of generic marketing language.
Before: A single product page with no category context. After: A product page plus 8 supporting pages covering specific use cases ("Acme CRM for real estate agents," "Acme CRM for agencies," "Acme CRM vs Salesforce"). Topic clusters signal domain expertise to ChatGPT's retrieval system.
Before: No review presence. After: 85 reviews on G2 (4.6 stars), 40 on Capterra (4.5 stars), 30 on Trustpilot (4.7 stars). Review platforms are among the most heavily represented sources in ChatGPT's training data. Each review adds a data point that reinforces your brand's entity signal.
Fix Technical Basics
A surprising number of "content problems" turn out to be crawl or rendering problems:
- Confirm AI crawlers are allowed in robots.txt
- Ensure key pages are actually crawlable (especially with heavy client-side rendering)
- Use pre-rendering where needed
- Add an llms.txt file (unproven, but cheap to try)
How Do I Get ChatGPT to Recommend My Brand?
Getting ChatGPT to recommend your brand requires building all three signals simultaneously: recognition (ChatGPT knows who you are), authority (third-party validation from reviews, press, and industry coverage), and relevance (your content explicitly addresses the queries users ask). Brands that only optimize one signal while neglecting the others consistently underperform.
The highest-leverage action for most brands is collecting reviews on G2, Capterra, and Trustpilot. Review platforms are heavily represented in ChatGPT's training data, and a strong review profile addresses both authority and relevance in one effort. Pair that with consistent entity descriptions across your website, social profiles, and third-party mentions.
Tactics for Claude, Gemini, and Perplexity
The recognition, authority, and relevance framework applies across all AI platforms, but each has its own quirks.
Claude searches the web in real-time. Build a positive presence in well-indexed, high-authority publications and industry sources. Claude's user base tends toward professionals and enterprise buyers.
Gemini leans heavily on Google's ecosystem and E-E-A-T signals. Build your Google Business Profile, pursue a Google Knowledge Panel, and use Schema.org structured data to reinforce entity relationships.
Perplexity cites its sources aggressively and transparently. It favors fresh, authoritative content. Maintain an active publishing cadence and front-load answers in your content structure.
For platform-specific deep dives, see How to Appear in Perplexity AI and How to Optimize for AI Overviews.
What ChatGPT Actually Searches
When ChatGPT has web browsing enabled, it searches to supplement its knowledge.
Based on our data, ChatGPT typically: - Runs 10-20 searches per response - Pulls 1-2 sources per search - Favors top-ranking results
This means traditional SEO still matters. If you rank well on Google for relevant queries, ChatGPT is more likely to find and cite you. But ranking alone isn't enough. ChatGPT also weighs authority and decides whether to trust what it finds.
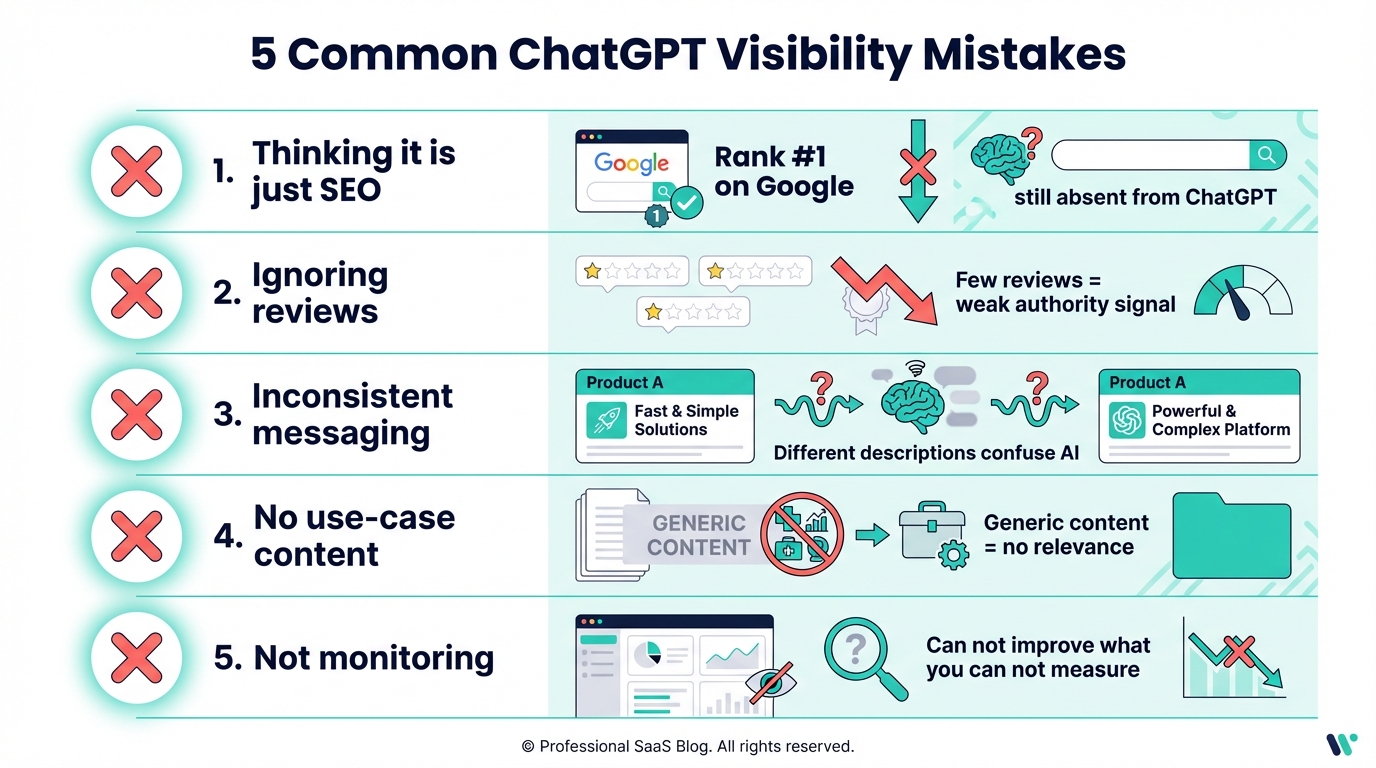
Common Mistakes
Thinking it's just SEO: Good SEO helps but isn't sufficient. You can rank #1 on Google and still be absent from ChatGPT.
Ignoring reviews: Reviews are heavily weighted. Brands with few reviews struggle.
Inconsistent messaging: If your positioning varies across sources, ChatGPT gets confused.
No use-case content: Generic content doesn't create relevance for specific queries.
Not monitoring: You can't improve what you don't measure.
Optimizing only for Google: ChatGPT's browsing mode uses Bing, not Google. Brands that rank #1 on Google but are absent from Bing's top results miss the browsing pathway entirely. Submit your sitemap to Bing Webmaster Tools and verify your Bing presence.
Inconsistent entity descriptions: If your homepage says "AI visibility platform," your G2 profile says "brand monitoring tool," and your LinkedIn says "marketing analytics software," ChatGPT receives conflicting signals. Pick one primary description and use it everywhere. Most brands have no idea how ChatGPT sees them.
Relying on a single platform: Different models lean on different external signals. Show up consistently across surfaces so the same entity and POV appear everywhere.
How to Track Your Results
Manual testing works but doesn't scale. A ChatGPT rank tracker automates this. friction AI runs hundreds of prompts across ChatGPT, Claude, Gemini, and Perplexity, tracking your visibility over time and flagging when mentions drop.
For manual testing, try these prompts:
- "What is [your brand]?" - Tests recognition
- "Best [your category] tools" - Tests inclusion
- "[Your brand] vs [competitor]" - Tests competitive positioning
- "Best [category] for [use case]" - Tests relevance
AI visibility is inherently noisy. Track rolling averages instead of one-off results. Directional change matters more than any single screenshot. Once you're optimized, here's how to track results: How to Track Your Brand's Visibility in ChatGPT.
For the complete framework, see How to Improve Your AI Visibility.
How Can I Check Brand Mentions in ChatGPT?
The simplest way to check is to ask ChatGPT directly. Open a fresh session (no prior context) and run 10-15 category queries like "best [your category] tools" and "[your category] for [use case]." Record whether your brand appears, how it's described, and which competitors are mentioned alongside you. Run each query 2-3 times since responses vary between sessions.
For ongoing monitoring, tools like friction AI automate this process by running hundreds of prompts across ChatGPT, Claude, Gemini, and Perplexity, tracking your mention rate, sentiment, and competitive position over time. Manual checking works for an initial baseline, but automated monitoring is necessary for tracking trends.
For industry-specific guidance, see our guide on get your SaaS product recommended by ChatGPT.
Is there a ChatGPT rank tracker?
Yes, though "rank" works differently than in Google. A ChatGPT rank tracker measures mention frequency, recommendation rate, and position within multi-brand answers across repeated queries. Tools like friction AI run the same prompts on a schedule, compare your brand against competitors in each response, and alert you when visibility changes. For the full tracking setup, see How to Track Your Brand's Visibility in ChatGPT.
Related Articles
- How to Track Brand Mentions in ChatGPT (2026 Guide)
- AI Citation Tracking: How to Monitor When AI Cites Your Brand
- How to Appear in Perplexity AI: Get Cited and Mentioned
- How to Optimize for Google AI Overviews (2026 Guide)
