By Joao da Silva and Maryanna Franco (BrilliantSEO) · June 6, 2026
TL;DR. We ran 14,140 controlled queries across five AI systems and found that brand strength, measured by Google Knowledge Graph
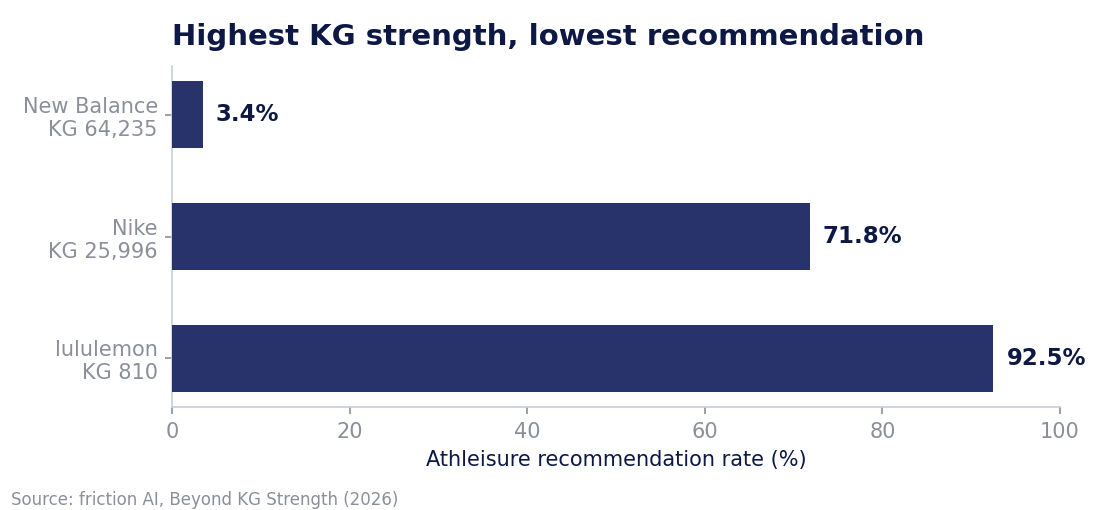
resultScore, predicts whether an AI recognizes your brand, not whether it recommends you. Inside the category an AI files you under, strength helps (KG score correlates with recommendation at +0.68, p=0.05). Across category boundaries it does nothing (−0.10, statistically zero). New Balance has the strongest Knowledge Graph entry in our whole sample and gets recommended for athleisure 3.4% of the time. Lululemon, with 1/79th the KG score, gets recommended 92.5% of the time. Here is what actually moves the second number.

An AI will happily tell you exactly who a brand is, then never recommend it.
That sentence is the whole study. Ask ChatGPT, Gemini, Claude, Perplexity, or Google's AI Overview "what is New Balance?" and all five answer correctly, every time. Ask the same five "what are the best athleisure brands?" and New Balance shows up in 3.4% of answers. Not because the models forgot it. Because they have it filed under footwear, and an athleisure question never opens that drawer.
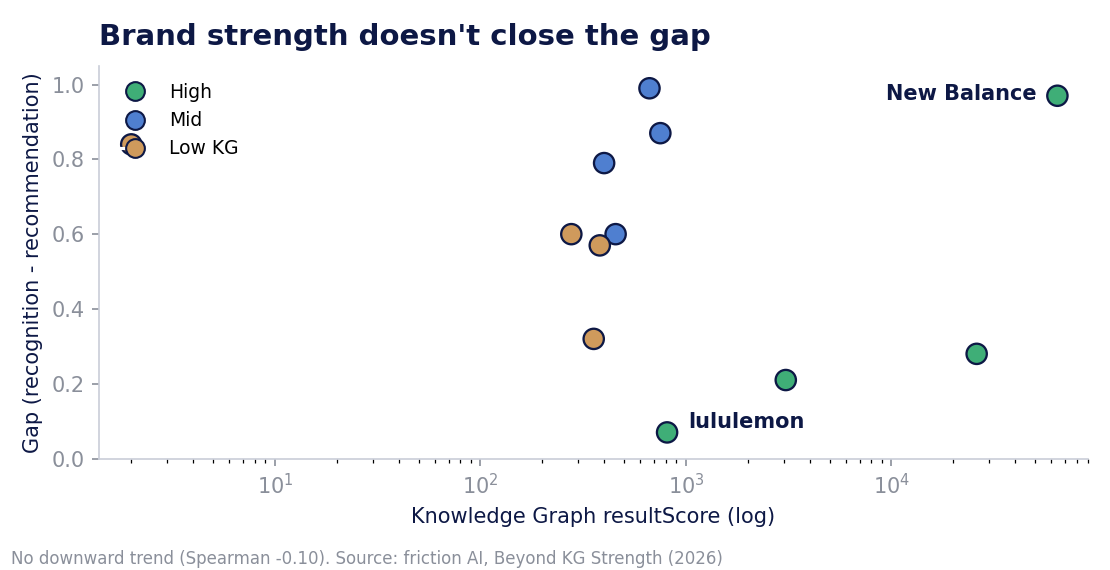
New Balance is not a weak brand. It holds the highest Google Knowledge Graph resultScore in our entire 12-brand sample (64,235, about 2.5 times Nike's). If brand strength bought recommendation, New Balance would dominate. It doesn't. Lululemon, sitting at a resultScore of 810, surfaces in 92.5% of athleisure recommendations. Both brands are recognized at essentially 100%. The gap between them is not awareness. It is something most AEO advice never names.
This is the pillar for a five-part study we ran with Maryanna Franco of BrilliantSEO, published in full as the white paper Beyond KG Strength (Franco & da Silva, 2026, DOI: 10.5281/zenodo.20331344). Below is the reframe, the five mechanisms that actually drive recommendation, and what to do about each. Every mechanism has its own deep dive.
Recognition is not recommendation
These are two different surfaces, and they are governed by two different mechanisms.
Recognition is what an AI says when you name your brand: "what is Acme?" Recommendation is what it says when you name a category and let it pick: "best tools for X?" Most brand teams optimize as if these were one problem. They are not.
The cleanest proof is the correlation split. Across all 12 brands, Knowledge Graph strength correlates with the recognition-recommendation gap at −0.10, which is statistically indistinguishable from zero. Strength alone does not close the gap. But narrow the lens to the nine brands the AIs file inside the apparel category, and KG strength correlates with athleisure recommendation at +0.68 (p=0.05). Inside your category, strength is a real multiplier. Across the boundary, it buys you nothing, even when the categories are adjacent.
That is the headline, and it is worth stating precisely so it isn't over-read: brand strength is not irrelevant. It earns recognition. It earns durability. And, as we'll see with Nike, it can earn a bridge into an adjacent category if the right conditions are met. What it does not do is transfer across a category boundary on its own. Strong brand, wrong drawer, no recommendation.
Once you see recognition and recommendation as separate surfaces, the obvious question is what governs the second one. The study found five mechanisms.
What actually drives recommendation: five mechanisms
1. Category Coding: the AI files you, and the file is sticky
Before an AI decides whether to recommend you, it has already decided what you are. We call this Category Coding: every model carries an internal category label for your brand, and a category query only considers the brands inside that category.
The striking part is the agreement. We probed all five models on what category each brand belongs to, and 9 of the 12 brands came back unanimous (4 of 4, or 3 of 4 with one near-synonym). Nike is footwear to all of them. Lululemon is athleisure to all of them. The models don't just share facts about brands. They share the same mental filing cabinet, and that filing cabinet acts like a cage. Where they disagree, behavior gets fuzzy in exactly the way you'd expect: Gymshark splits 2-2 between sportswear and athleisure across the models, and its athleisure recommendation rate lands in the middle at 40.5%.
You can't out-market your category code. Outdoor Voices spent years positioning itself as the athleisure brand. The models code it 28% athleisure and 81% sportswear, and recommend it accordingly. Marketing told one story; the published web told another, and the AIs learned from the web.
→ Deep dive: Category Coding: how AI sorts your brand before it recommends you
2. The KG-Hijacked Entity: when a bigger namesake owns your drawer
Category Coding fails completely when another entity owns your name in the Knowledge Graph. We call this a KG-Hijacked Entity.
TALA is a UK athleisure brand. Its Google Knowledge Graph description reads, verbatim, "Financial services company," because a larger Philippines-based fintech owns the TALA entity. When we probed the models directly, they correctly called the athleisure TALA an apparel brand. But in actual recommendation queries it surfaced 0% of the time, the lowest in the sample, and its recognition score was depressed to 0.32, against 0.99 for nearly every other brand. The label on the drawer was wrong, so the brand was invisible regardless of how it markets itself.
This one has a real fix, and it isn't content. It's a Google Knowledge Graph disambiguation request. Most brand teams have never been told the process exists.
→ Deep dive: The KG-Hijacked Entity: when AI confuses you with a bigger namesake
3. The Category Prototype: every category has a brand at its center
Categories aren't flat lists. Each one is a cluster of brands that get mentioned together, with one brand at the dead center. We call that center the Category Prototype.
For athleisure, it's lululemon, and the data is not subtle. Lululemon co-occurs with Alo Yoga 534 times, with Nike 482 times, and with Gymshark 264 times across recommendation responses. It is also the first brand named in most answers where it appears (average position 1.64, per the live study dashboard). New Balance, for contrast, co-occurs with lululemon 21 times. It sits outside the cluster as an unconnected node. To get recommended in a category, you have to enter that category's cluster, which means earning third-party content that places you next to the prototype.
One more thing the cluster revealed: it's bigger than the brands we pre-registered. The extractor surfaced more than 260 other brand names, and two we never put in the study, Athleta (74% of recommendation runs) and Vuori (71%), were mentioned more often than 9 of our 12 targets (study dashboard). The category, as the AIs construct it, is wider than any single brand's competitive set.
→ Deep dive: The Category Prototype: the brand AI thinks defines your category
4. Sub-Stream Strength: how Nike crosses a boundary New Balance can't
Nike breaks the rule, and the way it breaks it is the lesson. Nike is footwear-coded, exactly like New Balance, yet it gets recommended for athleisure 71.8% of the time. New Balance gets 3.4%. Same category code, opposite outcome.
The difference is what we call Sub-Stream Strength: a dense enough body of category-aligned third-party content to register as a real presence in the adjacent category. Nike has a large apparel sub-stream (decades of coverage about Nike leggings, Tech Fleece, sportswear), so it co-occurs with lululemon 482 times. New Balance co-occurs with lululemon 21 times. Nike built a bridge into athleisure through earned coverage, not by relabeling itself. You cross a boundary by building density on the other side, not by claiming you belong there.
→ Deep dive: Bridge Brands and Sub-Stream Strength: crossing into an adjacent category
5. The Coverage Gap: your own website barely counts
Here is the mechanism most marketing budgets get wrong. On recommendation queries, the brand's own website is almost never the source. We call the distance between what you publish and what AI cites the Coverage Gap.
The numbers are stark. On recommendation queries, a brand's own domain accounts for 0 to 3% of citations, topping out at 2.8% (Reebok). Lululemon has 3,736 third-party citations supporting its recommendations; New Balance has 144. Recognition runs on your own pages, and recommendation runs on third-party coverage in your category.
The smoking gun is New Balance's athleisure citations. When the models do cite something for New Balance in an athleisure context, the sources are dictionary sites: Merriam-Webster, Cambridge, Collins. There is no real third-party athleisure content about New Balance to retrieve, so the model falls back to looking up what the phrase "new balance" means. An empty drawer, on display.
→ Deep dive: The Coverage Gap: why your own site barely moves AI recommendations
The two surfaces, side by side
The recognition-recommendation split shows up cleanly in the citation data. Ask an AI "what is this brand?" and it leans on the brand's own domain. Ask it "best brands in this category?" and that same domain nearly vanishes.
| Surface | Question type | Where AI gets its answer |
|---|---|---|
| Recognition | "What is [brand]?" | The brand's own site (ChatGPT 49%, Perplexity 36%, Claude 23%, AI Overview 21%, Gemini 13% of citations) |
| Recommendation | "Best [category] brands?" | Third-party coverage (own site is 0-3%, max 2.8%) |
Per-LLM recognition shares from the live study dashboard; recommendation shares from the white paper.

Two surfaces, two mechanisms, two budgets. Optimizing your homepage harder will move recognition and do almost nothing for recommendation. The brands that win recommendation win it on other people's pages.
What to do with this
The study points to four moves, roughly highest-impact first:
- Probe your category code first. In one prompt, ask each model to categorize your brand. If the models disagree, or file you where you don't sell, that is your binding constraint, and no amount of homepage work fixes it.
- Check for a namesake collision. Look up your Google Knowledge Graph description. If it reads as the wrong company, you have a KG-Hijacked Entity problem, and the fix is a disambiguation request, not content.
- Earn category coverage, not just links. Recommendation is decided by third-party publications in your category. The metric that matters is corroboration density: how many independent sources in your target category reproduce what you want AI to say. Inbound link counts measure the wrong thing.
- If you're expanding categories, build the sub-stream. You don't bridge into an adjacent category by relabeling. You bridge by accumulating enough category-aligned coverage to register as a real presence, the way Nike did in apparel.
Methodology
The study in one line. 14,140 controlled API queries across 5 AI systems, 12 athletic-apparel brands, 10 prompts, 7 days, single UK exit, May 2026.
We ran 14,140 queries through friction AI's harness, of which 13,992 succeeded (98.95%). The five systems were ChatGPT (gpt-5), Gemini (gemini-2.5-pro), Claude (claude-opus-4-7), Perplexity (sonar-pro), and Google AI Overview (via SerpAPI), all with web search on. We tested 12 athletic-apparel brands stratified across three Knowledge Graph strength tiers, using Google KG resultScore as the proxy for brand strength. Ten prompts (5 recognition, brand-named; 5 recommendation, category-named) ran 5 times a day for 7 consecutive days, May 3 to 9 2026, from a single UK (London) exit at temperature 0.7. Responses were scored by an Anthropic Haiku-4.5 judge. Full method, every number, and the brand-by-brand data are in the white paper and the live study dashboard.
Two honest limits. This is a 12-brand pilot in one category and one geography, so treat the tier-level claims as directional and the per-brand cases as the durable evidence. And a small follow-up experiment, swapping athleisure prompts for footwear prompts, showed New Balance jumping from roughly 1% to 90% and lululemon dropping from 90% to 0%, which is the cleanest illustration we have that category, not strength, is the gate; but it ran on ChatGPT only, as a single pass, and is not part of the main 14,140-run dataset. We report it as a direction, not a result.
Disclosure: both authors are affiliated with friction AI, an AI brand visibility platform. friction AI is not one of the 12 brands studied. The white paper is ungated and the underlying data is published so the analysis can be checked independently.
FAQ
Does brand strength help AI visibility at all? Yes, but only on the recognition surface and inside your own category. Knowledge Graph strength correlates with recognition and, within a matched category, with recommendation (+0.68, p=0.05). It does not transfer across category boundaries (−0.10).
Why does AI recognize my brand but never recommend it? Because recognition and recommendation are different surfaces. Recognition reads your own site; recommendation reads third-party coverage in the category the AI has filed you under. If you have strong recognition and weak recommendation, you usually have a Coverage Gap, a Category Coding mismatch, or both.
How do I find out what category AI thinks my brand is in? Ask each model directly to categorize your brand in one prompt. Cross-model agreement is high (9 of 12 brands in our study were unanimous), so a single round of probes is usually enough to reveal your category code.
Does optimizing my website improve AI recommendations? Barely. On recommendation queries, a brand's own domain is 0-3% of cited sources. Your site drives recognition; third-party coverage in your category drives recommendation.
This is the pillar of a five-part series translating the Beyond KG Strength white paper into practice. Deep dives: Category Coding · The KG-Hijacked Entity · The Category Prototype · Bridge Brands and Sub-Stream Strength · The Coverage Gap. See the framework applied to 40 SaaS brands in our 40-brand AI visibility audit.