Research
19 May 2026 · 32 min read · By Maryanna Franco & Joao da Silva
# Beyond Knowledge Graph Strength: what 14,140 LLM queries revealed about brand visibility in generative AI
A controlled study across 12 athletic apparel brands and 5 large language models tested whether Knowledge Graph strength predicts brand surfacing in category-scoped recommendations. The intuition holds inside a brand's home category, where the signal is real but noisy. It collapses entirely across category boundaries. The variable that does the work is what we term Category Coding.
## Key takeaways
- Across the nine athleisure-coded brands in our sample, Spearman rank correlation between Google KG
resultScoreand athleisure recommendation rate is +0.68 (p = 0.05). Within a brand's coded category, stronger KG entities surface more reliably in category-scoped queries. Directionally dependable, but with substantial noise in the magnitude. - Across category boundaries the relationship disappears. The recognition–recommendation gap correlates with
resultScoreat −0.10 , statistically indistinguishable from zero. No reading of KG strength predicts whether a brand surfaces in queries outside its home category. - The headline disconfirmation of the KG-strength heuristic is the Nike / New Balance contrast. Both are KG-coded as "Footwear company". Nike (
resultScore25,996) surfaces in 71.8% of athleisure recommendation queries; New Balance (resultScore64,235) surfaces in 3.4%. Same Category Coding, structurally different cross-category behavior. - The variable that explains the asymmetry is Category Coding : the KG short-description field (e.g. "Apparel company", "Footwear company") combined with the category-aligned third-party content corpus that has accumulated around the entity. It is a property of the substrate, not of any one model.
- The recommendation signal flows almost entirely through third-party publication coverage. Brand-owned domains (lululemon.com, nike.com, newbalance.com) account for 0–3% of cited sources across all 11 brands with citation data. The maximum observed is 2.8% (Reebok). In recognition responses to the same brands, own-brand domains account for 16.0% of cited sources: the discounting is specific to comparative queries.
- Three brands lose recognition when web search is disabled. They are exactly the three brands without an English Wikipedia article. KG strength does not predict whether entity-level recognition survives without retrieval. Wikipedia presence does.
- One brand in the sample is functionally invisible because the KG description field resolves it to an unrelated larger entity. We term this state a KG-Hijacked Entity. The corrective action is structurally distinct from any other state in the framework: a disambiguation request to Google. Not content production.
## The intuition we tested
If you've worked on brand visibility in AI search since 2024, you've encountered the same operating assumption from a dozen different sources. The Knowledge Graph is treated as the central layer.
The reasoning is intuitive. If a brand has a well-formed entity in Google's Knowledge Graph (with a description, a resultScore, an English Wikipedia article), then large language models will know the brand exists. And if they know the brand, they'll surface it when a user asks the kind of category-scoped question those models increasingly answer: "best athleisure brands?", "recommend sportswear for everyday training?", "which athletic apparel brands are worth buying in 2026?"
The intuition is reasonable. It's also testable. And in mid-2026, with five generative answer systems serving category-scoped recommendations at scale, the cost of the test had finally come down to within reach of a small research budget. We wrote and ran one.
This article reports the headline findings. The full empirical study, 37 pages, six falsifiable predictions, and all the data, is deposited on Zenodo under CC-BY 4.0. The link is at the end.
### Why this matters now
The shift from blue-link search to generative-answer recommendation has changed the unit of measurement. In the blue-link world, a brand's question was "do we rank for the keyword?" The answer was discrete, single-source, and observable in the SERP. In the generative-answer world, the question is "does the LLM mention us when a user asks the category question without naming us?" The answer is probabilistic, multi-source, and not observable from the brand's own logs.
Practitioners have responded to the shift in two ways. The first is to keep operating on SEO instincts: invest in own-content and entity authority, and assume those translate into AI recommendation. The second is to invest in Knowledge Graph optimization specifically: cleaning up the entity, claiming the Knowledge Panel, building Wikidata sitelinks. Both responses presuppose that recognition predicts recommendation. The data in this study says the relationship is more conditional than either response assumes.
## What we did
We selected 12 athletic apparel brands stratified across three a-priori KG-strength tiers, then validated the tiering against fetched Google Knowledge Graph resultScore values:
| Tier | Brands | resultScore range |
|---|---|---|
| High KG | New Balance, Nike, Alo Yoga, lululemon | 810 – 64,235 |
| Mid KG | Sweaty Betty, Reebok, Outdoor Voices, Rhone Apparel | 400 – 751 |
| Low KG | Varley, TALA, Gymshark, LNDR | 2 – 381 |
The score range spans roughly four orders of magnitude, from LNDR at resultScore = 2 to New Balance at 64,235. That is what a controlled test of the KG-strength hypothesis requires. If the hypothesis is true, the surfacing rate should track that gradient.
### The 5 LLMs
Five generative answer systems were queried via API with web-search grounding enabled. We chose API access over browser-driven simulation because it removes one entire layer of variability (session state, personalization, geo-IP localization, anti-bot detection) and replaces it with a known-spec call.
| System | Provider | Model identifier | Search grounding |
|---|---|---|---|
| ChatGPT | OpenAI | gpt-5 |
Responses API with tools=[{"type":"web_search"}] |
| Gemini | gemini-2.5-pro |
Tool(google_search=GoogleSearch()) |
|
| Claude | Anthropic | claude-opus-4-7 |
Messages API with web_search tool |
| Perplexity | Perplexity | sonar-pro |
Native search grounding |
| AI Overview | SerpAPI proxy | (Google AI Overview) | SerpAPI grounding |
All systems were configured with temperature = 0.7 and a single fixed UK geography (London exit). VPN compliance was enforced at the harness layer: runs refused to start if ipinfo.io/json.country did not return GB.
### The 10 prompts
Two prompt classes, five prompts in each, locked at study initiation.
Recognition (5 templates, brand-substituted at run-build time): "What does {brand} do?" , "Describe {brand}" , "Tell me about {brand}" , "What company is {brand}?" , "What is {brand}?".
Recommendation (5 verbatim, athleisure / sportswear shared): "Best athleisure brands?" , "Top 10 athleisure brands?" , "What brands do you recommend for athleisure?" , "Recommend sportswear labels for everyday training?" , "Which athletic apparel brands are worth buying in 2026?".
The recommendation prompts are not brand-substituted. Each recommendation run is scanned at extraction time for all 12 target brands, which lets the same recommendation run populate every brand's recommendation_rate simultaneously and dramatically reduces total run volume.
### Run volume and protocol
5 runs per day per cell × 7 consecutive days, May 3–9 2026. Total: 14,140 LLM responses , of which 13,992 succeeded (98.95%). 148 returned no_overview_shown on the Google AI Overview channel, which is a legitimate terminal state, not a failure.
| Run type | Computation | Total |
|---|---|---|
| Recognition (web-search ON) | 5 templates × 12 brands × 5 LLMs × 5 runs/day × 7 days, partial × ON arm | 8,268 |
| Recognition (web-search OFF) | 5,040 | 5,040 |
| Recommendation | 5 prompts × 5 LLMs × 5 runs/day × 7 days | 875 |
| Diagnostics, warm-up, retries | residual | ~957 |
| Total succeeded | 13,992 |
### How we scored responses
Recognition responses were scored by an Anthropic Haiku-4.5 judge on a three-point rubric: 0.0 for confusion or wrong-entity identification, 0.5 for partial recognition or clarification request, 1.0 for full correct identification. The judge's rationale was stored alongside each score for auditability.
Recommendation responses were processed by a separate Haiku extractor that scanned each response for mentions of the 12 target brands, with canonicalisation via aliases ("lulu" → "lululemon"; "New Balance Athletics" → "New Balance"). Two metrics fall out: mention_rate (any mention) and recommendation_rate (named in a list, table, or explicit recommendation phrasing). The latter is the primary outcome reported throughout.
## Headline finding 1: KG strength is directional within a category
Within the nine athleisure-coded brands in our sample, KG resultScore rank-orders brands against observed surfacing in the direction the practitioner intuition predicts. The Spearman correlation between resultScore and athleisure recommendation rate is +0.68 (exact permutation p = 0.05). Across all twelve brands without holding category constant, it is +0.41 (p = 0.18).
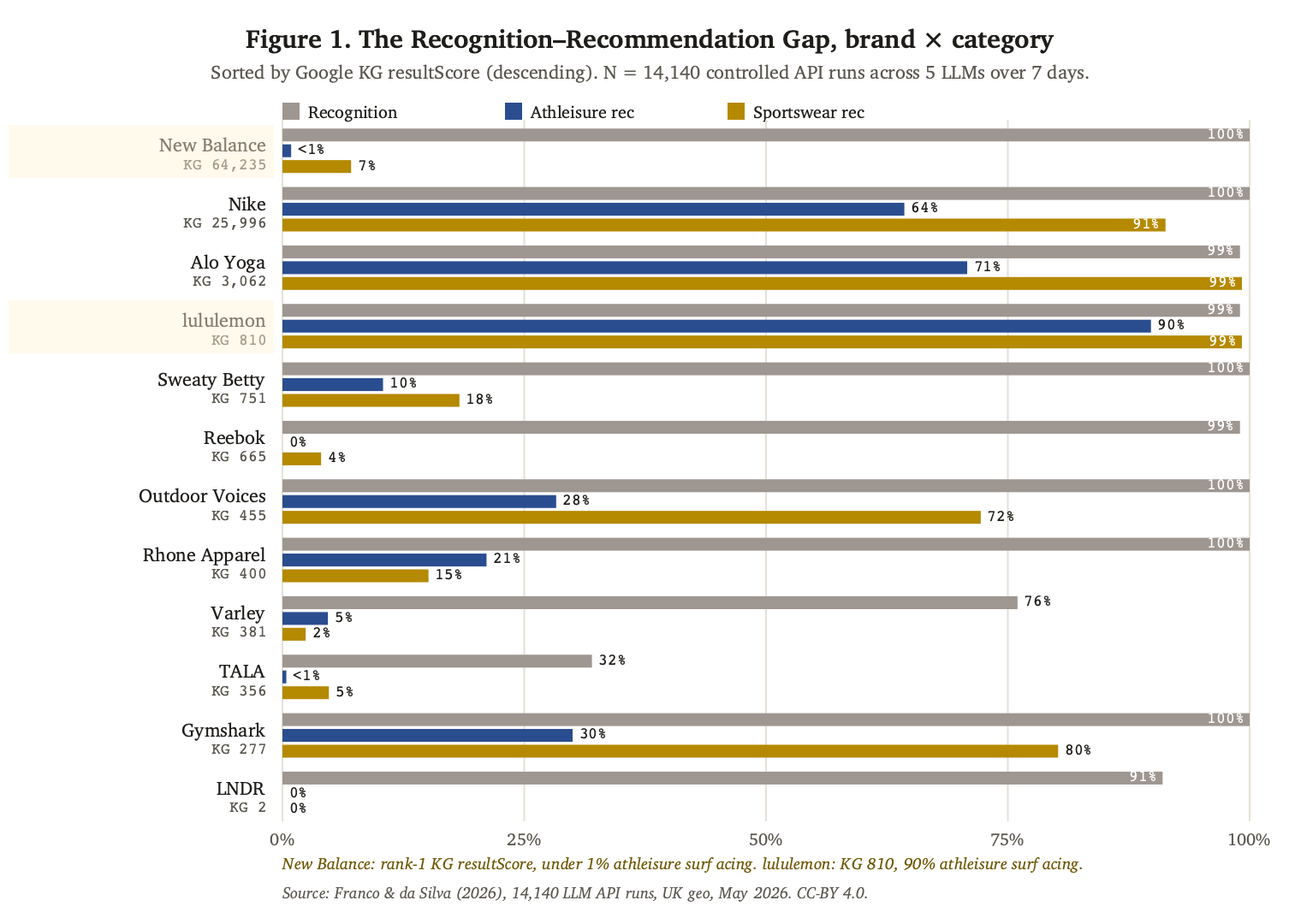
Figure 1. The Recognition–Recommendation Gap. Rows: the 12 brands sorted descending by Google KG resultScore. The recognition column is near-solid at 1.0 across all twelve brands; the athleisure and sportswear recommendation columns are sparse and category-asymmetric. The sort order is itself the demonstration that KG strength does not predict the cross-category gap.
How much weight that +0.68 can carry is the question to be careful with. It clears the conventional significance threshold, but it sits exactly on it, and it rests on n = 9 with a floor-clustered tail. The three lowest-footprint brands in the set (Varley, TALA, LNDR) sit concordantly low on both resultScore rank and surfacing, and they carry much of the correlation. None has an English Wikipedia article. Removing those three to isolate the Wikipedia-present subset (n = 6) drops the correlation to +0.43 (p = 0.42), no longer significant.
The reading we settle on. The within-category directional relationship is robust to specification. The magnitude is not, at this sample size. resultScore is a usable indicator of the direction of within-category surfacing, and a poor indicator of its magnitude. Gymshark (resultScore 277) surfaces in athleisure recommendation roughly three times as often as Sweaty Betty (resultScore 751). Alo Yoga (3,062) and lululemon (810) are surfacing peers despite a factor-of-four resultScore difference. The informative contrasts are between brands separated by an order of magnitude or more, not by one or two tiers.
### One further limit: correlation is not cause
The brands at high resultScore in this sample also have larger marketing budgets, longer commercial histories, more category-aligned third-party coverage, and more co-occurrence in third-party listicles than the brands at low resultScore. Any of those covariates could be doing the work the resultScore correlation registers. Raising resultScore through Knowledge Graph cleanup changes one variable, and it does not follow that within-category surfacing would move with it.
The within-category result is best read as a directional indicator of where to look (toward strong KG entities), not as an actionable lever in itself. The actionable mechanisms developed in the next sections are what move the needle on the ground.
## Headline finding 2: KG strength is silent across category boundaries
Across category boundaries the relationship disappears. The recognition–recommendation gap measured across categories correlates with resultScore at −0.10 , statistically indistinguishable from zero. resultScore is a directional signal of surfacing inside a brand's category-coded domain; it does not carry the brand into an adjacent category.
The headline disconfirmation is the Nike / New Balance contrast.
| Brand | KG resultScore |
KG description |
LLM probe (4/4) | Athleisure rec rate | Sportswear rec rate |
|---|---|---|---|---|---|
| New Balance | 64,235 | "Footwear company" | athletic_footwear | 3.4% | 7% |
| Nike | 25,996 | "Footwear company" | athletic_footwear | 71.8% | 91% |
| Reebok | 665 | "Sporting goods company" | athletic_footwear | 0.7% | 4% |
| lululemon | 810 | "Apparel company" | athleisure_apparel | 92.5% | 99% |
Nike and New Balance occupy the same Knowledge Graph state. Same description, same probed category, similar order of magnitude on resultScore. The framework predicts that neither should surface in athleisure. Nike surfaces in 71.8% of athleisure recommendation queries. New Balance in 3.4%. KG strength runs the wrong way between them. The lower-resultScore footwear brand is the one that crosses categorical lines.
Reebok, the third footwear-coded brand in the sample, behaves as the framework predicts. Surfaces at 0% in athleisure. Nike is the single outlier among the three footwear-coded brands. The mechanism that makes Nike anomalous is developed later in this article as Bridge Brand status. What we want to establish first is that resultScore, high or low, does not predict cross-category surfacing at all.
lululemon at resultScore 810 surfaces in 92.5% of athleisure queries. Far above New Balance at resultScore two orders of magnitude higher. No directional reading of KG strength predicts that pattern. The variable that does is the brand's category coding.

Figure 2. KG resultScore against athleisure recommendation rate. The within-category positive signal is visible inside the athleisure-coded cluster (lululemon at the top-left, Alo Yoga, Gymshark). The cross-category collapse is visible in the footwear-coded brands: New Balance at the highest resultScore sits at the bottom-right, Nike Bridges, Reebok does not. TALA is hijacked.
## The Recognition–Recommendation Gap
The relationship between what a large language model recognizes about a brand and what it recommends in a category-scoped query is the central observation this article formalises. The two are separable. The same brand-entity, with the same Knowledge Graph anchor, can be recognized at 1.00 and recommended at 0.01 within the same category query.
We define the operational terms tightly:
- Recognition (operational): the language model correctly identifies a brand when the brand is named in the prompt. Scored 0.0 / 0.5 / 1.0 by the Haiku judge, averaged across 5 prompt templates × 5 LLMs × 5 runs per day × 7 days.
- Recommendation (operational): the language model surfaces the brand unprompted in response to a category-scoped query. Measured as
recommendation_rate, the rate at which the brand is named in the response across 5 recommendation prompts × 5 LLMs × 5 runs per day × 7 days, per category. - The Recognition–Recommendation Gap is per brand per category:
gap_score = recognition_score − recommendation_rate.
Per-category framing is what does the work here. Nike surfaces in 71.8% of athleisure recommendation queries and 91% of sportswear. New Balance in 3.4% of athleisure and 7% of sportswear. The same brand-entity occupies different operational positions in adjacent category queries.
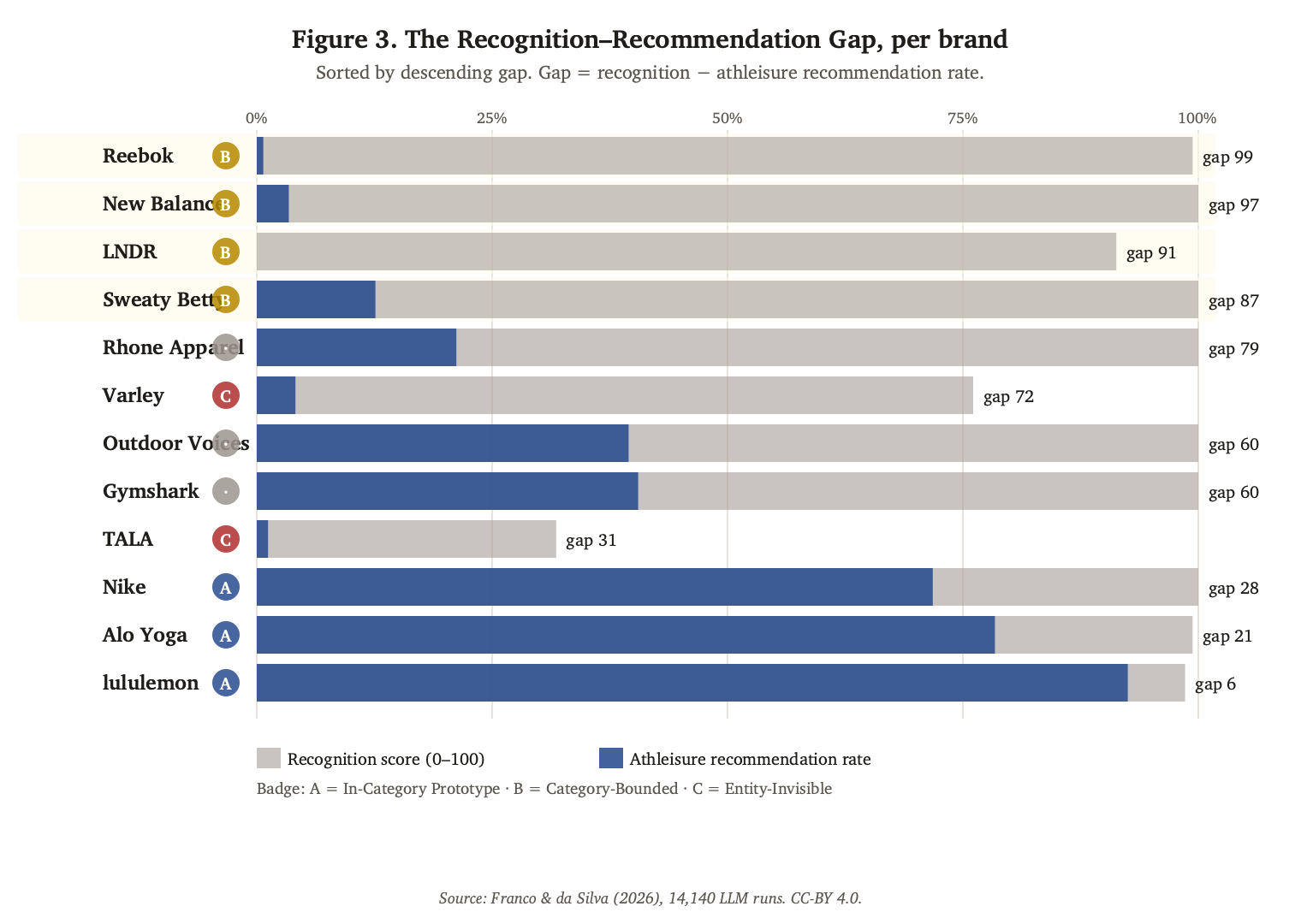
Figure 3. The Recognition–Recommendation Gap per brand, sorted by descending gap. Gray bar = recognition score (0–100). Navy bar = athleisure recommendation rate. The width difference is the gap. Badge A = In-Category Prototype, B = Category-Bounded, C = Entity-Invisible. The light-yellow rows isolate Sub-Case B brands, where recognition is near-perfect and recommendation is near-zero.
### Three sub-cases of the gap
From the 12-brand sample, three structurally distinct states emerge, each with its own diagnostic signature.
#### Sub-Case A. In-Category, recognized, recommended
The brand is recognized at near-1.0 AND surfaces frequently in the category query. In our sample: lululemon (recognition 0.99, athleisure recommendation 0.93), Alo Yoga (recognition 0.99, athleisure recommendation 0.78). The model has both entity-level identification of the brand and a category-level association strong enough that the brand is selected when the category is the gate.
The brand that defines the category in LLM output (the densest node in the co-occurrence network) is what we term the Category Prototype. In our athleisure data, lululemon co-occurs with Alo Yoga 534 times, with Nike 482 times, and with Gymshark 264 times. The Category Prototype state is self-reinforcing. Third-party publications increasingly cluster their treatments around the prototype, which deepens the prototype's category coding, which raises the prototype's recommendation rate.

Figure 4. The Category Prototype as the densest node in the athleisure co-occurrence network. Each edge is the count of co-mentions across 875 recommendation runs. lululemon co-occurs with Alo Yoga 534 times, with Nike 482 times, with Gymshark 264 times. The cluster the prototype defines is the cluster the model retrieves to answer the category query.
#### Sub-Case B. Category-Bounded. Recognized, not recommended
The brand is recognized at 1.0 and surfaces at near-zero in the category query. The canonical example is New Balance: recognition 1.0 across all five LLMs and 14,140 controlled runs, athleisure recommendation 3.4%. Reebok shows the same pattern (0.7% athleisure, 4% sportswear).
Recognition is entity-anchored: the model knows the brand exists, can describe it, can answer questions about it. Recommendation requires a category-anchored sub-stream of corpus content that the brand lacks for this category. The asymmetry is the canonical Category-Bounded Gap state.
Diagnostically, the Category-Bounded state matters because it's the one practitioners under-recognize. A brand operating here has expended the budget on entity-level KG presence and is losing the visibility race in the target category not for lack of recognition, but for absence in the category-aligned corpus. The corrective action is not more brand awareness; it's third-party content in publications the LLM actually retrieves from.
#### Sub-Case C. Entity-Invisible. Not recognized, not recommended
The brand is not reliably recognized AND does not surface. In our sample, this state is cleanly instantiated only by TALA, and TALA is a special variant treated separately below.
The intended non-hijacked example is LNDR (resultScore 2). It receives 0% recommendation in both categories. But under web-search grounding, the model still recognizes LNDR at 0.91 when the brand name is supplied directly. LNDR is therefore not Entity-Invisible on the recognition axis under retrieval. It is a Category-Bounded brand (Sub-Case B) with a negligible Knowledge Graph footprint.
That web search grounding makes entity-level recognition cheap, even for a resultScore 2 brand, is itself a finding. The pure form of Sub-Case C may be rare once retrieval is in the loop.
A structurally distinct variant of Sub-Case C: the brand name resolves in Google's Knowledge Graph to an unrelated larger entity, and the apparel brand is functionally invisible despite some apparel-context corpus presence. TALA in our study resolves to a financial-services entity (description "Financial services company"). We term this variant a KG-Hijacked Entity.
The KG-Hijacked state is the most actionable failure mode in practice. The failure has a specific causal mechanism, entity disambiguation in the substrate, rather than diffuse corpus scarcity. The corrective lever is structurally different from any other. A Knowledge Graph disambiguation request to Google, after which the recommendation behavior is hypothesised to shift. We commit to that hypothesis as a falsifiable prediction in §11 of the full paper.
## Category Coding: the mechanism
The relationship that explains the cross-category asymmetry is between the Knowledge Graph short-description field, the third-party content corpus that has accumulated around the entity within a given category, and the category that the language model surfaces the brand in. We formalise that relationship as Category Coding : the property of a brand-entity by which the combination of (a) the Knowledge Graph short-description field and (b) the category-aligned third-party content corpus determines which category the entity is surfaced under in language-model output.
Category Coding is a property of the substrate the LLM trained on and retrieves from, not a property of the model itself. That is why the five LLMs in our study agree on category assignments where the substrate is unambiguous, and disagree where the substrate is ambiguous.
A caveat the rest of this section depends on. Category Coding is a joint property of two layers we cannot fully disentangle with the present sample: the KG description field and the category-aligned third-party corpus that accumulates around the entity. The two travel together in our 12-brand set. Brands with a specific KG description also tend to have richer category-aligned coverage, and brands with thin corpora also tend to have generic descriptions. Prediction 3 (§11.3) is the natural experiment that would isolate the description layer from the corpus layer, by changing the KG description for one brand while the corpus stays constant. Until that experiment runs, the framework treats the two layers as a joint mechanism and is explicit that the corpus may be doing more of the work than the description.
### The mechanism, as a directed chain
Google KG entry → Short
descriptionfield ("Footwear company", "Apparel company") → Category-aligned third-party publications produce category-coded content → Training data + retrieval indexes populate with category-coded content about the brand → LLM internalises (brand → category) mapping; retrieval surfaces the same mapping → Category determines whether brand surfaces in "best [category] brands?"
Brand agency declines down the chain. The corrective lever for a Category-Bounded Gap sits at the description-field and third-party-publications layers, not at the brand's own site.
### Three operational Category Coding states
Empirical examination of the 12-brand sample identifies three structurally distinct Category Coding states, distinguished by the form of the KG description field.

Figure 5. Category Coding states across the 12 brands. KG description field combined with LLM probed category, grouped by coding state. Hijacked = the KG description anchors to an unrelated entity (TALA → Financial services company). None = generic "Company" descriptor or no description, contestable through third-party content investment.
| Brand | KG description |
Probed LLM category (4/4 unless noted) | Coding |
|---|---|---|---|
| Nike | Footwear company | athletic_footwear (4/4) | Specific |
| New Balance | Footwear company | athletic_footwear (4/4) | Specific |
| Reebok | Sporting goods company | athletic_footwear (4/4) | Specific |
| lululemon | Apparel company | athleisure_apparel (3/4 + 1 yoga) | Specific |
| Alo Yoga | Apparel company | yoga_wellness (3/4 + 1 athleisure) | Specific |
| Outdoor Voices | Fashion company | athleisure_apparel (4/4) | Partial |
| Sweaty Betty | Retail company | athleisure_apparel (3/4) | Weak |
| TALA | Financial services company | athleisure_apparel (4/4) | Hijacked |
| Gymshark | (generic "Company") | mixed | None |
| Rhone Apparel | (generic "Company") | mixed | None |
| Varley | (generic "Company") | mixed | None |
| LNDR | (no description) | athleisure_apparel (4/4) | None |
Three groups follow.
Specific KG description group. Brands with a meaningful free-text description (Nike, New Balance, Reebok, lululemon, Alo Yoga, Outdoor Voices) have a strong category anchor. The LLM's probed-category assignment is unanimous or near-unanimous across the four directly-probed systems, and the recommendation behavior is predictable from the description. The description does not determine whether the brand recommends within its assigned category. It determines that the brand is category-coded to that category in the model's representation, regardless of whether sufficient category-aligned corpus exists to support recommendation.
Generic-description group. Brands with a generic "Company" description or no description (Gymshark, Rhone, Varley, LNDR) have no KG anchor; the LLM falls back on training-data co-occurrence patterns from third-party content alone, a fallback behaviour consistent with the prior literature on LLMs as parametric knowledge stores (Petroni et al., 2019) and the long-tail-knowledge constraints documented by Kandpal et al. (2023). Behavior in our sample is variable: Gymshark, which has invested heavily in apparel-coded third-party content over the past several years, surfaces at 40.5% athleisure despite the generic description; LNDR, which has not, surfaces at 0%.
The generic-description state is contestable in a way the Specific and Hijacked states are not. A brand in this group can shift its observable category coding by accumulating category-aligned third-party content, without a Knowledge Graph correction request.
Hijacked KG Entity group. The KG description anchors the brand to an unrelated larger entity (TALA → "Financial services company"). The model's probed category for the apparel brand can be correct (athleisure_apparel, 4/4), but the description-driven Category Coding pulls the brand toward the wrong category-aligned corpus, and the recommendation rate in the intended apparel category is zero.
### Cross-LLM convergence on category labels
Direct probing of the five systems with the prompt "categorize brand X into one of: athletic_footwear / athleisure_apparel / performance_sportswear / yoga_wellness" produces 9 of 12 brands with unanimous (4/4 or 3/4 with a near-synonym) category assignment. The brands with internal LLM disagreement are diagnostic:
- Gymshark : 2/2 sportswear vs 2/2 athleisure. Empirical recommendation rate: 40.5% athleisure / 80% sportswear. Disagreement at the probe stage predicts mid-range recommendation behavior at the recommendation stage.
- lululemon : 3/4 athleisure, 1/4 yoga (Claude). Reflects lululemon's yoga heritage within an athleisure-coded recent corpus.
- Alo Yoga : 3/4 yoga_wellness, 1/4 athleisure (Perplexity). The reverse pattern: Perplexity treats Alo as broader athleisure where the other models hold the yoga anchor.
The convergence pattern is consistent with Category Coding being a property of the shared substrate, not of any individual system's training procedure. Where the substrate is unambiguous (Nike → athletic_footwear, 4/4), the systems agree. Where the substrate is ambiguous (Gymshark), the systems disagree, and the disagreement at the probe stage predicts the observable behavior at the recommendation stage.
## The Information Vacuum
Category Coding is necessary but not sufficient for In-Category recommendation. A brand can be category-coded correctly and still fail to surface, if the third-party corpus the LLM retrieves from contains no category-aligned content about it. We term this state the Information Vacuum.
The Information Vacuum is empirically observable. The citation source mix is the observation that establishes it.
### Own-content is functionally invisible
Across all 11 brands with citation data in our recommendation arm, own-brand domains (lululemon.com, nike.com, newbalance.com) account for 0–3% of cited sources. The maximum observed share is Reebok at 2.8%. Four of the eleven brands with citation data have zero own-brand citations.
| Brand | Own-brand citations | 3rd-party citations | Own % |
|---|---|---|---|
| lululemon | 50 | 3,736 | 1.3% |
| Alo Yoga | 2 | 3,177 | 0.1% |
| Nike | 43 | 2,726 | 1.6% |
| Gymshark | 28 | 1,744 | 1.6% |
| Outdoor Voices | 9 | 1,426 | 0.6% |
| Rhone Apparel | 0 | 1,143 | 0.0% |
| Sweaty Betty | 1 | 635 | 0.2% |
| Varley | 0 | 232 | 0.0% |
| New Balance | 0 | 144 | 0.0% |
| TALA | 0 | 38 | 0.0% |
| Reebok | 1 | 35 | 2.8% |
The pattern is uniform. The LLM almost never references the brand's own website when explaining a recommendation. The recommendation signal flows almost entirely through third-party publication coverage.
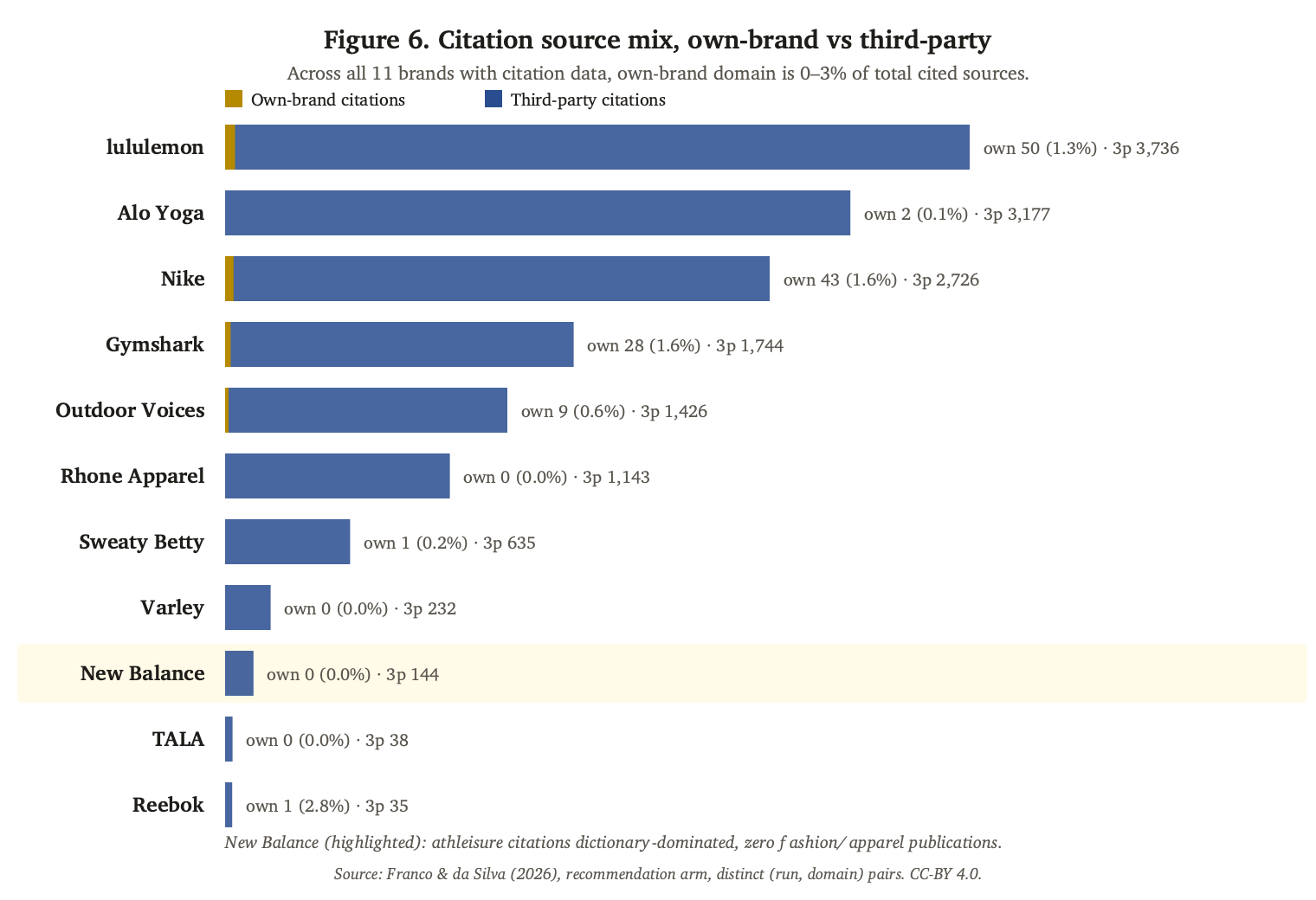
Figure 6. Citation source mix by brand. Across all 11 brands with citation data, own-brand share is 0.0–2.0% of total cited sources. New Balance's bar is the smoking-gun visual: not only is own-content invisible, the third-party citation pool itself is small (156 total) and structurally distinct.
The recommendation arm is the informative half of a within-study contrast. The same citation extraction applied to the recognition arm, where the model is asked about the brand by name, produces a different mix entirely. Across the web-search-on recognition runs, own-brand domains account for 16.0% of cited sources (5,240 of 32,830 distinct run–domain pairs), against 0.9% (134 of 15,170) in the recommendation arm: roughly eighteen times the share. Every brand's own domain clears 10% in recognition responses.
| Brand | Own-brand citations | 3rd-party citations | Own % |
|---|---|---|---|
| LNDR | 864 | 2,302 | 27.3% |
| lululemon | 674 | 2,069 | 24.6% |
| Varley | 476 | 2,152 | 18.1% |
| Nike | 507 | 2,363 | 17.7% |
| Outdoor Voices | 380 | 2,087 | 15.4% |
| Gymshark | 338 | 1,859 | 15.4% |
| Sweaty Betty | 410 | 2,397 | 14.6% |
| New Balance | 392 | 2,654 | 12.9% |
| Alo Yoga | 314 | 2,267 | 12.2% |
| TALA | 329 | 2,658 | 11.0% |
| Rhone Apparel | 291 | 2,396 | 10.8% |
| Reebok | 265 | 2,386 | 10.0% |
No clean KG-strength gradient is present in the recognition-arm shares (LNDR, the lowest-KG brand, is highest at 27.3%, but lululemon sits second at 24.6%), and the table is reported without a gradient claim. The contrast that carries the finding is between arms, not between brands: the model cites the brand's own site freely when asked about the brand, and almost never when ranking brands within a category.
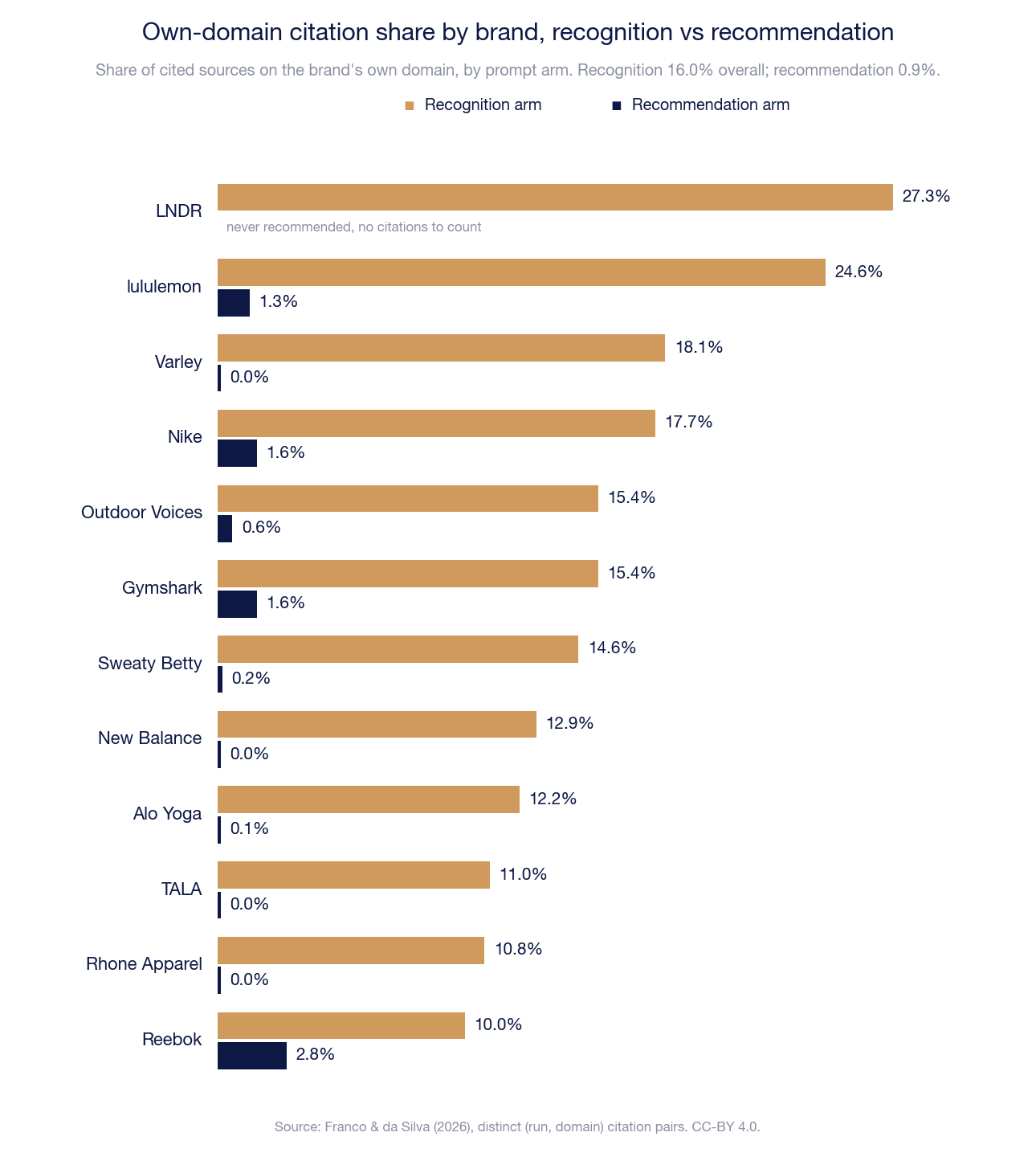
Figure 6b. Own-domain citation share by brand, recognition arm vs recommendation arm. Same computation as the tables above (distinct run–domain pairs). Every brand's own domain exceeds 10% of cited sources in recognition responses; the recommendation-arm maximum is 2.8%. LNDR shows no recommendation bar: it was never recommended, so there were no citations to count.
### The New Balance dictionary-citation signature
New Balance's athleisure citation pool contains zero fashion or apparel publications. Instead, it is dominated by dictionary sites. Merriam-webster.com, dictionary.cambridge.org, vocabulary.com, collinsdictionary.com, yourdictionary.com, at substantially higher rates than any apparel or fashion publication. The pool also includes generic YouTube and Facebook links, but contains zero fashion or apparel-publication citations.
The dictionary citations are the diagnostic signal of the Information Vacuum. When the model has nothing topical to say about New Balance in an athleisure context, it falls back on generic phrase-lookup sources, citing definitions of the phrase "new balance", because no body of athleisure-coded third-party content about the brand exists for retrieval to surface. The fallback behaviour is consistent with the calibration literature on retrieval failure modes (Mallen et al., 2023; Wallat et al., 2025): when the retriever returns nothing topical, the model substitutes lexical sources rather than abstaining.
The Information Vacuum is the corpus-level state that produces the Category-Bounded behavior observed in New Balance: correctly recognized, correctly Category Coded as a footwear brand, and absent from athleisure recommendations because no category-aligned corpus has been populated about it in the athleisure category specifically.
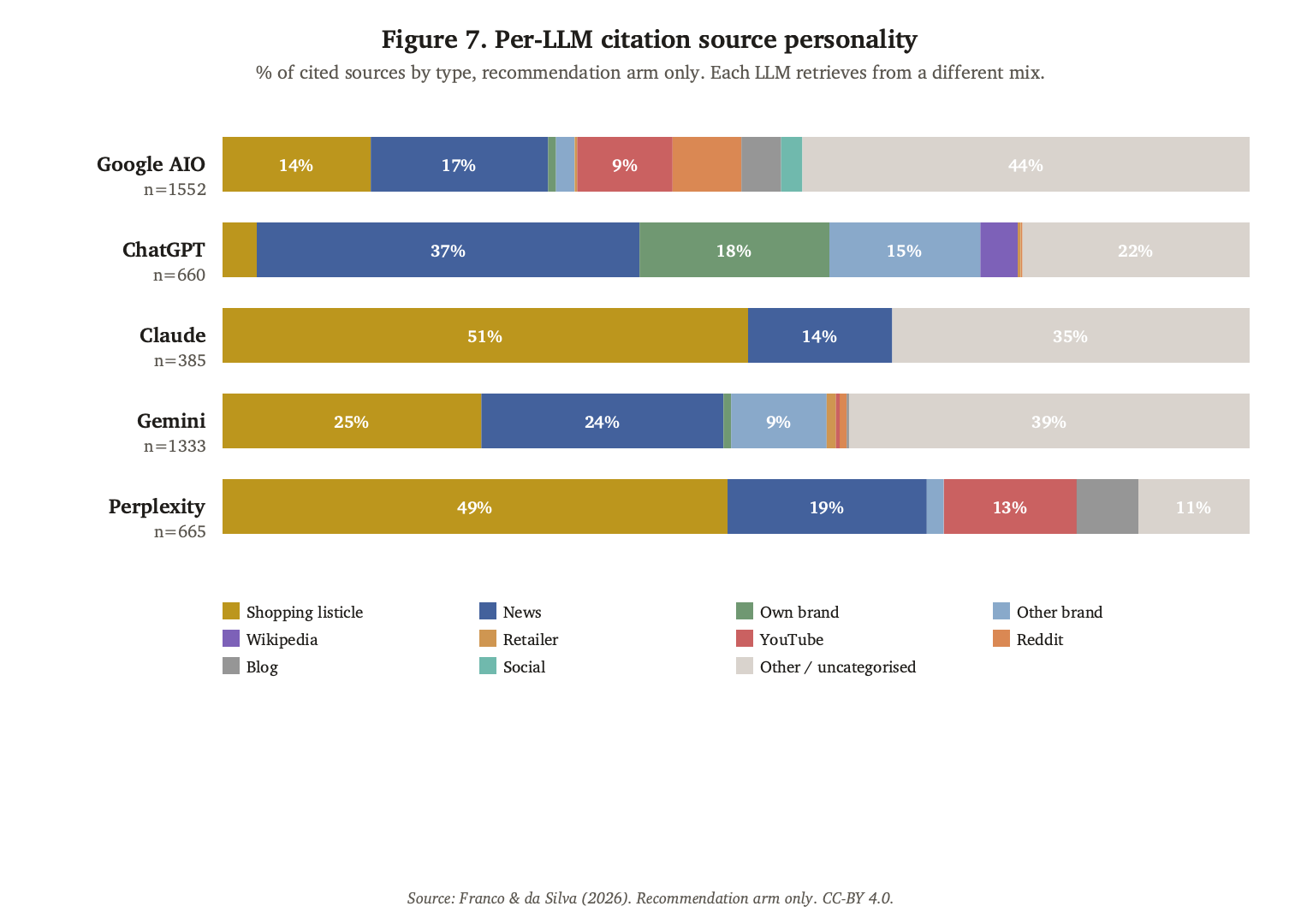
Figure 7. Each LLM retrieves from a structurally different mix of source types. ChatGPT leans news-heavy with the highest own-brand share (18%). Claude's recommendation citations are dominated by shopping-listicle aggregators. Gemini and Perplexity cite shopping listicles heavily. Google AI Overview shows the most diverse mix. The corpus an LLM retrieves from is the corpus that shapes its recommendations.
The per-system mix in Figure 7 aggregates both prompt arms. Split by arm, the own-domain share separates sharply by system: ChatGPT 40.1% in recognition responses against 7.1% in recommendation responses; Perplexity 22.5% against 0.0%; Claude 18.0% against 0.0%; Google AI Overview 14.9% against 0.2%; Gemini 7.9% against 0.2% (distinct run–domain pairs per system; recognition arm web-search-on). Two of the five systems never cite brand-owned domains in recommendation responses at all. The recommendation-side discounting established above is therefore not an artifact of one engine's retrieval design: it is shared behaviour across all five systems, with only ChatGPT retaining a residual own-domain share when recommending.
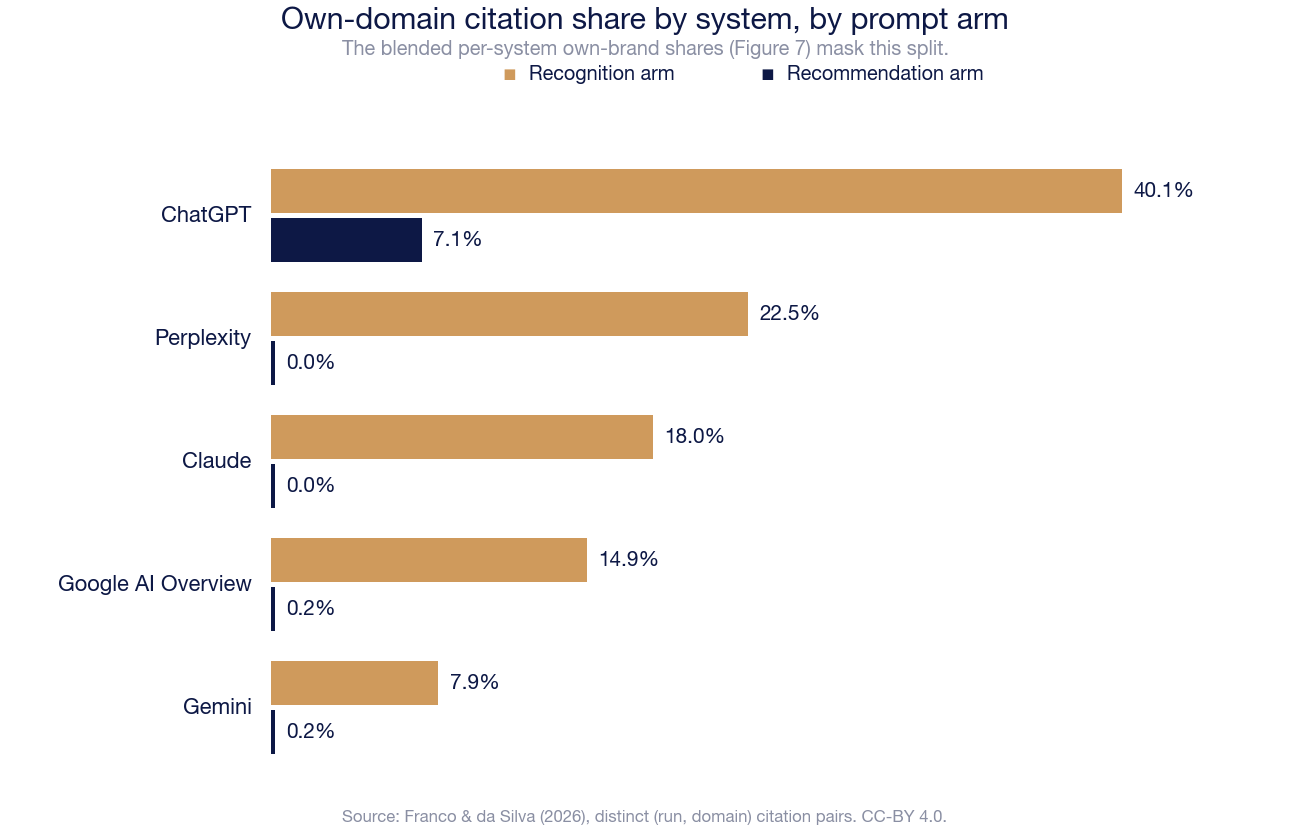
Figure 7b. Own-domain citation share by system, split by prompt arm. The blended per-system shares in Figure 7 mask the split: ChatGPT is the only system with a non-negligible own-domain share in recommendation responses.
### Why own-content gets discounted
The recognition–recommendation citation contrast above measures the discounting directly: the same systems, brands, and week produce a 16.0% own-brand citation share when the query is entity-scoped and 0.9% when it is comparative. The interpretation (consistent with framing-theoretic accounts of categorical salience and with Wallat et al. 2025 on RAG faithfulness) is that the language model has learned to discount promotional self-description in favour of third-party comparison content for queries that require ranking or selecting among brands. Brand websites typically describe their own products without comparative context; comparison-aware authority for "best X brands?" queries lives in third-party publications, Wikipedia, retailer taxonomy, and listicle aggregators.
The model's hedging behavior on under-corroborated brands is consistent with this account. The implication for brand teams is concrete. Optimizing the company's own marketing site cannot substitute for third-party coverage in the target category. Brands operating in the Category-Bounded state need investment in publications the LLM retrieves from (trade press, comparison sites, category-specific magazines), not in their own marketing site.
## Web search as a recognition backstop
Every system in our recommendation arm was queried with web-search grounding enabled. The recognition arm, however, ran in both conditions: 8,268 web-search-on recognition runs and 5,040 web-search-off. The contrast isolates what web search contributes to entity recognition, and the answer is specific: web search functions as a recognition backstop for brands absent from the model's parametric memory, and for those brands only.
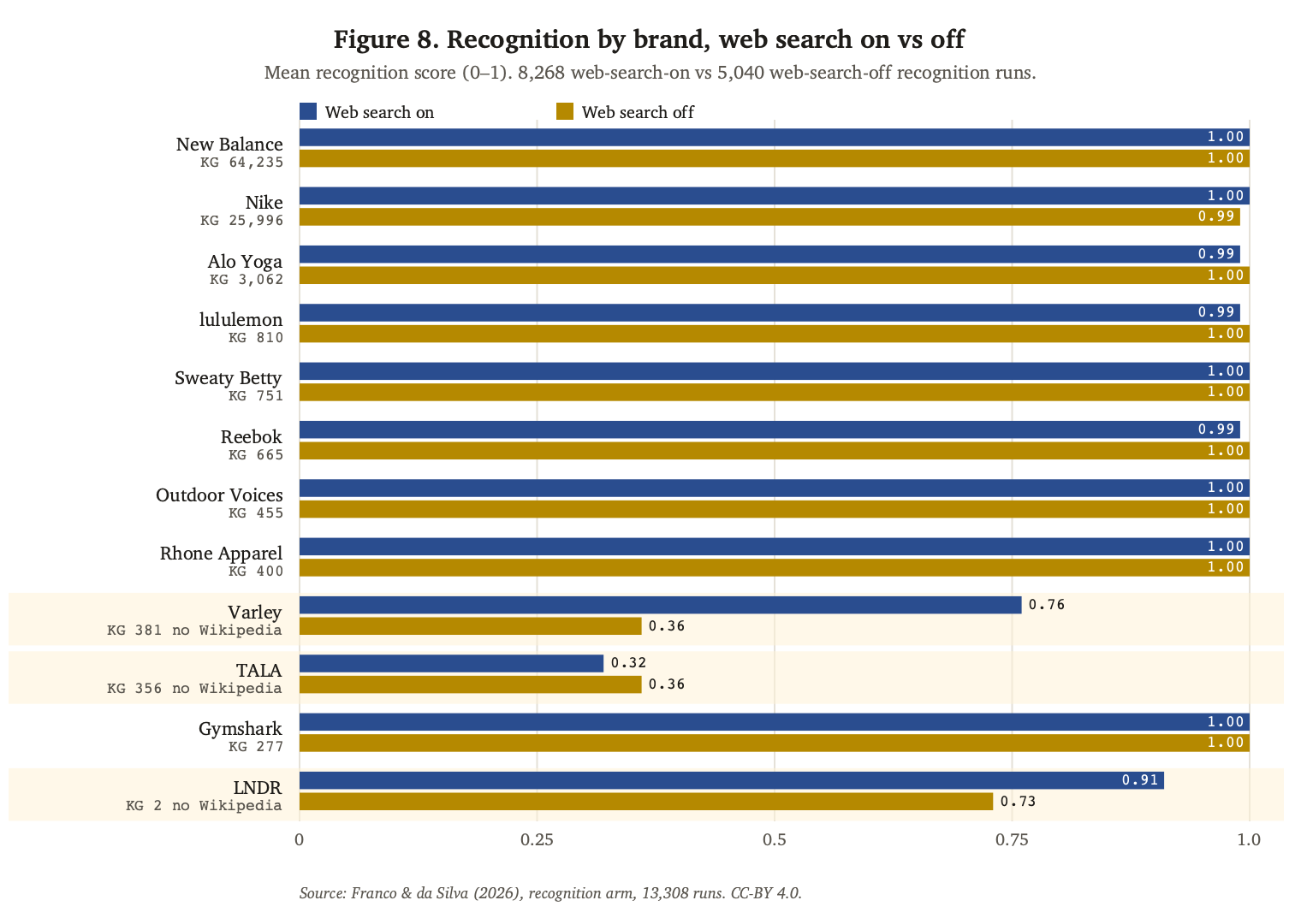
Figure 8. Recognition by brand, web search on vs off. Rows: the 12 brands sorted descending by Google KG resultScore. Each brand shows mean recognition score (0.0–1.0) under web-search-on (8,268 runs) and web-search-off (5,040 runs) conditions. Nine brands are recognized at or near 1.0 in both conditions. The three brands without an English Wikipedia article (Varley, LNDR, TALA) are the only ones whose recognition falls when retrieval is removed. The effect tracks Wikipedia presence, not KG resultScore.
### Recognition survives without search, for brands Wikipedia already knows about
For nine of the twelve brands, recognition is effectively unchanged between the two conditions: mean recognition score is at or near 1.0 with web search on and with it off. This group spans the full KG range, from Nike (resultScore 25,996) down to Gymshark (resultScore 277). KG strength does not predict whether a brand survives the loss of retrieval.
Three brands diverge. Varley drops from 0.76 with search to 0.36 without it; LNDR drops from 0.91 to 0.73; TALA is low in both conditions (0.32 with search, 0.36 without). These three brands are exactly the three with no English Wikipedia article.
The brand the web-search-off condition penalises is not the low-resultScore brand; it's the brand absent from the Wikipedia-anchored corpus that dominates LLM pretraining data. Gymshark, with a lower resultScore (277) than Varley (381) but an established English Wikipedia article, is recognized at 1.0 in both conditions. Varley, with the higher resultScore but no Wikipedia article, collapses without retrieval.
### TALA: the instructive exception within the exception
TALA is the KG-Hijacked Entity. It confirms the framework's distinction between entity-resolution failures and parametric-memory failures. TALA is poorly recognized whether or not search is available. Turning retrieval on does not rescue it, because retrieval is misdirected toward the unrelated financial-services entity that occupies TALA's Knowledge Graph slot.
Web search is a backstop for the absence of an entity from parametric memory. It is not a backstop for an entity collision in the substrate. The KG-Hijacked state is corrigible by Knowledge Graph disambiguation, not by retrieval.
### The implication
Entity-level recognition has two possible sources: parametric memory (the brand was learned during pretraining) and retrieval (the brand is looked up at inference time). For a brand with an established Wikipedia presence, parametric memory alone is sufficient and web search adds nothing to recognition. For a brand absent from Wikipedia, parametric memory is thin, and recognition depends on retrieval; remove retrieval and recognition falls.
The practitioner consequence is bounded but concrete. A brand absent from Wikipedia is recognized by current systems only because those systems retrieve at query time, and that recognition is contingent on a configuration the brand does not control. If a system answers from parametric memory alone, or down-weights retrieval, a Wikipedia-absent brand loses even entity-level recognition, the floor on which all category surfacing rests.
## Bridge Brands and cross-category surfacing
The four sub-cases developed so far (In-Category Prototype, Category-Bounded, KG-Hijacked, and the broader Entity-Invisible state) cover four of the five operational states a brand can occupy in category-scoped LLM output. The fifth state, a brand that is Category Coded to one category but surfaces strongly in an adjacent one, is empirically rare and operationally important. We term this state the Bridge Brand condition.
### Nike as the canonical Bridge Brand
Nike is the only Bridge Brand in our 12-brand sample. KG-coded as "Footwear company", probed unanimously as athletic_footwear by all four directly-probed LLMs, Nike surfaces in 71.8% of athleisure recommendation queries and 91% of sportswear recommendation queries. New Balance, identically Category Coded (KG description "Footwear company", probed unanimously as athletic_footwear), surfaces in 3.4% of athleisure queries. The two brands occupy the same Category Coding state and produce structurally different recommendation behavior.
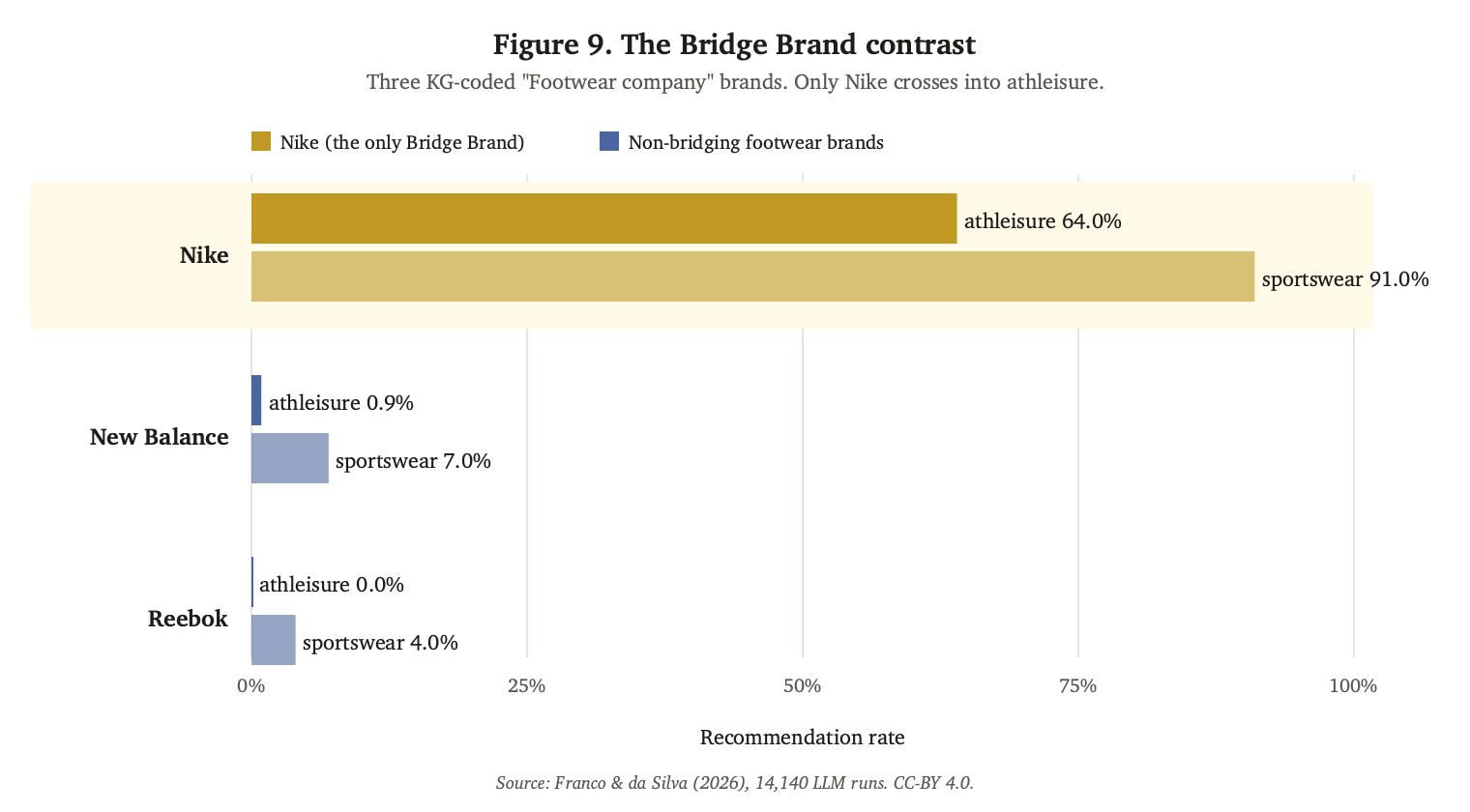
Figure 9. Three KG-coded "Footwear company" brands, two category framings. Nike (highlighted) crosses into athleisure at 64% and dominates sportswear at 91%. New Balance and Reebok, identically Category Coded, do not bridge. The mechanism is Sub-Stream Strength: Nike has accumulated a category-aligned athleisure sub-stream large enough to register against its primary footwear coding.
The mechanism, as we develop it, is what we term Sub-Stream Strength : a brand's accumulation of category-aligned third-party content in a target category sufficient to register as a distinct signal alongside the brand's primary Category Coding.
### Sub-Stream Strength as the mechanism
Bridge Brand behavior requires a strong sub-stream in the target category sufficient to register as a distinct signal that the language model blends with the brand's primary category coding. Nike has a prominent apparel sub-stream (Nike Sportswear, Tech Fleece, Nike leggings) that has accumulated substantial category-aligned third-party coverage in apparel-coded publications. New Balance does not. Its apparel offering is operationally present, but the category-aligned corpus in apparel is thin.
The supporting evidence is co-occurrence. Nike co-occurs with athleisure-coded brands in our sample at substantially higher rates than New Balance does. Nike × lululemon: 482 co-mentions across the recommendation runs. New Balance × lululemon: 21. The Nike apparel sub-stream is large enough in the substrate to register as a separate signal that the language model recognises as athleisure-eligible despite Nike's primary footwear coding.
Sub-Stream Strength is therefore the mechanism for Bridge Brand status. A brand cannot Bridge by re-categorising itself. The Knowledge Graph description is what it is. A brand can Bridge by accumulating a sub-stream of category-aligned third-party content in the target category sufficient to register as a distinct signal alongside the primary Category Coding.
### Empirical rarity
Among the 12 brands in the sample, Nike is the only athletic_footwear-coded brand that crosses into athleisure at substantial rates. Reebok (KG description "Sporting goods company", probed as athletic_footwear unanimously) does not Bridge (0% athleisure). New Balance, with substantially higher KG strength than either, does not Bridge.
The pattern observed within the sample (one Bridge Brand out of three plausible candidates) is consistent with the framework's account of why Bridging is rare. It requires sustained third-party investment in a category-aligned sub-stream large enough to register against the primary category coding. The investment is observable post-hoc in citation patterns and is not equivalent to brand awareness or own-content production.
By the numbers
14,140. Controlled LLM responses across 5 systems over 7 days
3.4% vs 92.5%. Athleisure recommendation rate, highest-KG vs mid-KG brand
+0.68 / −0.10. Spearman ρ within-category vs across category boundaries
0–3%. Own-brand share of cited sources across all 11 brands
9 of 12. Brands whose recognition is unchanged by removing web search
3 of 3. Brands that lose recognition are the 3 without an English Wikipedia article
## A worked example beyond athletic apparel
The framework's empirical anchor is a single category vertical, athletic apparel. To illustrate that the four operational states are not specific to apparel, consider a hypothetical mid-tier B2B cybersecurity vendor: a fifteen-year-old firm with established enterprise customers, documented case studies in the security-vendor trade press (e.g. Dark Reading , SC Magazine), and a Knowledge Graph description of "Cybersecurity company". The vendor wants to surface in category-scoped recommendation queries within the security space ("best identity and access management vendors?", "top cloud security platforms?"). It observes that despite reliable name-recognition by language models, it does not surface unprompted.
The framework predicts the diagnostic. Category Coding: the KG description is specific and category-correct ("Cybersecurity company"), placing the vendor in the Specific group; the vendor is not Hijacked (not Sub-Case C variant). Recognition–Recommendation Gap state: if the vendor is correctly recognized when named but absent from category-scoped queries, the vendor occupies Sub-Case B (Category-Bounded Gap), and the sub-category (IAM, cloud security, MDR, etc.) is the binding category framing.
Information Vacuum: the diagnostic is the third-party citation mix the model produces when asked the category question. If the vendor's citation pool for "best IAM vendors?" includes its own site at ≤3%, fashion or generic publications at 0%, and security-vendor trade publications at substantial rates, the vendor is not in Vacuum and the absence is for another reason. If the vendor's citation pool includes generic news sites and analyst-firm reports without trade publications, the vendor is in Vacuum within the specific sub-category framing of the query.
The framework's corrective recommendation is the same as for New Balance: invest in third-party trade-publication coverage in the specific sub-category framing the vendor wants to surface within. Bridge Brand status, by analogy, would correspond to a vendor that surfaces in multiple security sub-categories (IAM and cloud security and MDR) through Sub-Stream Strength in each.
The stylised case is offered to illustrate the framework's portability across verticals, not as evidence that the framework has been validated outside athletic apparel. Validation across categories is the basis for Prediction 2 in the full paper.
## Limitations
The framework and findings advanced here are bounded by limitations we name explicitly.
### Sample size and tier statistics
The brand sample is n = 12, with four brands per a-priori KG tier. The sample is small for any tier-by-tier statistical claim and should be treated as a pilot rather than as an established generalisation. A planned v2 study would extend to 30+ brands within a category.
### Category coverage
The study covers a single category framing pair (athleisure × sportswear) within a single broader vertical (athletic apparel). The framework's predictions for cross-vertical generalisation are not empirically tested in v1.0.
### Geographic coverage
The study was conducted from a single UK exit over seven consecutive days. Results may differ in the US, EU, and MENA regions; LLM and retrieval-index behavior can be geo-conditional in ways the present design does not isolate.
### Time boundedness
The five LLMs have differing training cutoffs, and the KG description that drove a model's category assignment at the time of querying may be older than the model's apparent recency. KG corrections, including the disambiguation requests hypothesised in the predictions section, take time to propagate across both the substrate (Wikipedia, third-party publications) and the model's internalised representations. The time horizon for measurable shifts is hypothesised at 12–18 months.
### Author-affiliation disclosure
The authors are affiliated with friction AI, a commercial entity operating in the AI brand visibility space. The framework's adoption would directly benefit the authors' commercial interests. This conflict of interest is disclosed; the empirical methodology, data, and extraction code are published as supplementary material at the same level of detail required for independent replication. No worked example in this paper uses friction AI's own brand position or commercial work as evidence of the framework's validity.
### Extractor and classifier coarseness
The Haiku-4.5 brand extractor and the source-type classifier (own-brand / comparison / news / blog / dictionary / other) have known limitations. The extractor produces duplicate rows from re-runs, handled by distinct-run-id sets for the rate computations. The source-type classifier marks many domains as 'other'; the per-domain analysis underlying the Information Vacuum section is more reliable than the type-aggregated buckets. The Information Vacuum signature (dictionary citations) is robust to this limitation because the dictionary domains are correctly classified and the signal is observable at the domain level.
### Observable proxy limitations
The study measures observable LLM output behavior (citation frequency, recommendation rate, recognition rate, co-occurrence patterns) as proxies for the underlying retrieval and synthesis mechanisms. The proxies are imperfect. A model may produce a recommendation that does not faithfully reflect its retrieval, and a model may suppress retrieval results without leaving an observable trace.
The study design mitigates single-snapshot artifacts through 5× per-prompt repetition across 7 days. The residual proxy limitations are accepted, and the falsifiable predictions in §11 of the full paper commit the framework to observable consequences specifically, accepting that the underlying mechanisms remain partially inaccessible.
## Testable predictions for replication
The framework generates six predictions. Each can be evaluated through controlled experimentation against the methodology established earlier in this article and would constitute confirmation or disconfirmation under the conditions specified. The full test designs, including statistical thresholds and disconfirmation criteria, are in §11 of the linked academic paper.
- Geographic replication. The Category-Bounded Gap pattern observed in our UK sample will replicate when the same brand sample is queried from US, EU, and MENA exits. Specifically, the New Balance / lululemon inversion against KG strength is hypothesised to persist in at least three of four geographies.
- Cross-vertical replication. The four-state framework (Sub-Case A / B / C with KG-Hijacked variant; Bridge Brand state) will be observable in brand samples from at least two adjacent verticals (skincare and B2B SaaS are the proposed candidates), with Category Coding producing analogous outcomes through analogous KG description fields.
- KG disambiguation causally shifts Category Coding. A successful Google Knowledge Graph disambiguation request, separating the apparel-brand TALA from the financial-services entity that currently occupies its KG slot, will produce a measurable shift in TALA's athleisure
recommendation_ratewithin 12–18 months. Confirmation: TALA's athleisure recommendation rate increases by at least 10 percentage points within the test window. This is the natural experiment that isolates the KGdescriptionfield from the third-party corpus held constant, and is the test the framework needs to convert Category Coding from a joint mechanism into a single-layer causal account. - Cross-LLM probe disagreement predicts recommendation behavior. Brands for which the four directly-probed LLMs disagree on category assignment at the probe stage will exhibit mid-range recommendation rates (30–70%) in the categories where the disagreement is observed. Brands with unanimous probe agreement will exhibit either high (>70%) or low (<30%) recommendation rates.
- Information Vacuum signature is diagnostic. The dictionary-citation signature observed in New Balance is predictive of Sub-Case B (Category-Bounded) state. Brands with ≥20% of their target-category citations sourced from dictionary domains are hypothesised to have
recommendation_rate< 10% in that category, regardless of recognition or KG strength. - Web search backstops recommendation surfacing, not only recognition. Under a web-search-off recommendation arm, a Wikipedia-absent brand will surface in category-scoped recommendation queries at a rate at or near zero, while a Wikipedia-present brand's recommendation rate will fall by a smaller margin.
## Conclusion and recommendations
Knowledge Graph strength is widely treated as the primary variable for AI brand visibility. The 14,140-run study reported here finds that the variable does carry a directional signal of surfacing within a brand's coded category (useful for direction, not for magnitude), and no signal at all across category boundaries. The variable that does carry across category boundaries is what we term Category Coding. The combination of the Knowledge Graph short-description field and the category-aligned third-party content corpus that has accumulated around the entity.
The framework identifies four operational states a brand can occupy in category-scoped LLM output (In-Category Prototype; Category-Bounded; Entity-Invisible, with the KG-Hijacked Entity variant; Bridge Brand) and one underlying mechanism for the cross-category Bridge condition (Sub-Stream Strength). The corpus-level failure mode the framework names, the Information Vacuum, is empirically diagnostic through the dictionary-citation signature observable in retrieval output. The corrective lever operates on the third-party publication layer rather than on the brand's own site (which accounts for 0–3% of cited sources in recommendation responses across our sample).
### What this means for brands operating today
- Treat KG
resultScoreas a directional indicator of within-category surfacing. Useful for prioritising work, not for predicting cross-category outcomes. Do not assume KG strength carries the brand into adjacent categories. - Diagnose your KG
descriptionfield. A generic "Company" descriptor places you in the contestable Generic-description group; a specific-but-mismatched descriptor (apparel brand coded as "Financial services company") places you in the KG-Hijacked group with a structurally distinct corrective lever. - Measure your citation source mix in the target category. A pool dominated by dictionary domains is the Information Vacuum signature; a pool with no fashion / trade / category-specific publications confirms the diagnosis. Investing in own-content while in Vacuum is a misallocation.
- To Bridge into an adjacent category, the lever is accumulating category-aligned third-party content in the target category's publication mix, sufficient to register as a distinct Sub-Stream alongside your primary Category Coding. Re-categorising the brand's own positioning will not do it.
- Wikipedia presence (a binary, trivially checkable property) is the variable that keeps entity recognition stable when retrieval is unavailable. KG
resultScoredoes not predict this. For brands absent from Wikipedia, recognition is contingent on a configuration the brand does not control. - If your brand is in a KG-Hijacked state, the corrective action is a Google Knowledge Graph disambiguation request, not more content production. We commit to this hypothesis as a falsifiable prediction with a 12–18 month test window.
- Practitioner intuition treats AI visibility as a single problem with a single lever. The data here is consistent with at least three structurally distinct levers (entity disambiguation; category-aligned third-party publication coverage; Wikipedia presence) operating at different layers of the substrate. Diagnose first, optimise second.
- The earned-vs-owned distinction articulated by AEO practitioners maps cleanly onto the present findings. Owned content (the brand's own marketing site) matters for long-tail entity questions where the brand is named directly. Earned content (third-party publication coverage in the target category) is what determines which category the model places the brand in and whether the brand surfaces in head queries like "best athleisure brands?". Investment ratio should follow the function: own-content for entity recognition where it matters, earned coverage for category placement.
### Future work
A v2 study at 30+ brands within a single category, replicated across at least two adjacent verticals and three additional geographies, would address the sample-size and external-validity limitations of v1.0. The KG-disambiguation prediction is on a 12–18 month clock from the disambiguation request submission; we plan to track the prediction through monthly recommendation-rate measurements. Methodologically, a follow-up arm with the Haiku extractor replaced by an entity-grounded extractor would tighten the per-domain citation classification.
## Methodology appendix
### Brand sample selection and KG fetching
The 12 brands were selected to span four orders of magnitude on resultScore within a single category vertical. Provisional tier assignment was made from public knowledge of the brands' commercial scale; final tier assignment is data-driven, by tertile split of the fetched resultScore values. KG resultScore values were fetched via the Google Knowledge Graph Search API (entities:search endpoint) at study initiation (2 May 2026) and stored in the study database. All brands were queried under identical prompt format, language, and API call structure, so cross-brand rank ordering is internally consistent.
### Scoring rubric
Recognition scoring rubric (Haiku-4.5 judge):
- 0.0. Confusion, wrong entity, or "I don't recognize this"
- 0.5. Partial recognition, clarification request, or "do you mean X?"
- 1.0. Full correct recognition
Recommendation extraction (Haiku-4.5): scans each response for mentions of the 12 target brands with canonicalisation via aliases. Two metrics fall out: mention_rate (any mention in the response) and recommendation_rate (named in a list, table, or explicit recommendation phrasing). recommendation_rate is the primary outcome reported.
### Statistical methods
Spearman rank correlations were computed across the relevant brand subsets. Significance was evaluated by exact permutation test rather than the asymptotic approximation, the latter being unreliable at n = 9 and n = 12. The within-category correlation (n = 9 athleisure-coded brands) excludes the three footwear-coded brands (New Balance, Nike, Reebok) for which athleisure is a cross-category query.
ρspearman(resultScore, ath_rec_rate) = +0.68, exact permutation p = 0.05
The robustness check (Wikipedia-present subset, n = 6) drops the three brands without an English Wikipedia article to isolate the floor-clustered tail; the correlation falls to +0.43 (p = 0.42). The +0.68 is significant with the floor-clustered tail included and not significant without it. The robust claim is the directional one; the magnitude is left for confirmation in the planned 30-brand v2.
### Reproducibility
The study database schema, prompt set, brand list, KG resultScore values at study initiation, and extraction code are published alongside the academic deposit under CC-BY 4.0. Reproducing the study requires API access at the listed providers (OpenAI, Google AI Studio, Anthropic, Perplexity, SerpAPI) and a UK exit IP for geo parity; total LLM cost was approximately $290 + extractor cost approximately $11.
About the authors
### Maryanna Franco
Maryanna Franco is the founder of BrilliantSEO and a fractional CMO. She partnered with friction AI for the present study, contributing methodology design and analytical review. She has no operational role at friction AI.
### Joao da Silva
Joao da Silva is co-founder of friction AI. He led the platform architecture and methodology for the present study.
Read further
- Full academic paper · 37 pages · CC-BY 4.0
Beyond Knowledge-Graph Strength: How Category Coding Drives Brand Visibility in Generative AI , Franco & da Silva (2026), Zenodo → - Companion practitioner guide
How to track brand mentions across AI platforms → - See your own brand in this study's lens
Request a friction AI demo →
This study was designed and executed at friction AI in May 2026 by Maryanna Franco (BrilliantSEO) and Joao da Silva (friction AI). The full dataset, prompt set, and extraction code are published under CC-BY 4.0 alongside the Zenodo deposit. Suggested citation: Franco, M. & da Silva, J. (2026). Beyond Knowledge-Graph Strength: How Category Coding Drives Brand Visibility in Generative AI (Version 1.1). Zenodo. https://doi.org/10.5281/zenodo.20331344