AI assistants are increasingly used to summarize vendors, compare options, and answer brand questions, but they can still misidentify brands, conflate similarly named entities, or describe outdated positioning. This is not automatically a failure of your marketing execution. It is an AI brand recognition problem rooted in how generative systems interpret language, entities, and uncertainty.
Generative AI does not "know" brands
Most large language models are not a canonical database of companies, products, or organizations. They generate responses by predicting likely text based on patterns learned during training and whatever information is available at response time.
Depending on the product and mode, an answer may be shaped by:
- Model training data, which can be incomplete, outdated, or noisy.
- Retrieved web sources, such as pages the system fetches to answer the question (availability and depth vary by system).
- Connected data sources, for example integrations or enterprise connectors where enabled.
- Conversation context, including what the user has already said and what the model has already assumed.
When a brand name appears in a prompt, the system may not verify the real world identity in a deterministic way. Instead, it selects an interpretation that appears most plausible given the available signals. That makes brand recognition probabilistic, contextual, and inherently uncertain.
Ambiguous entities as a systemic weakness
Many brand names collide with:
- Common nouns
- Technical terms
- Geographic references
- Other brands or products
When ambiguity exists, the system has multiple valid candidates. If the prompt or retrieved sources do not provide strong anchors, misattribution becomes more likely.
This is the practical reason brands get confused with competitors, a place name, or a generic meaning. It is not always because the assistant is "hallucinating" in the colloquial sense. Often it is making a plausible selection under uncertainty and then continuing as though that selection were correct.
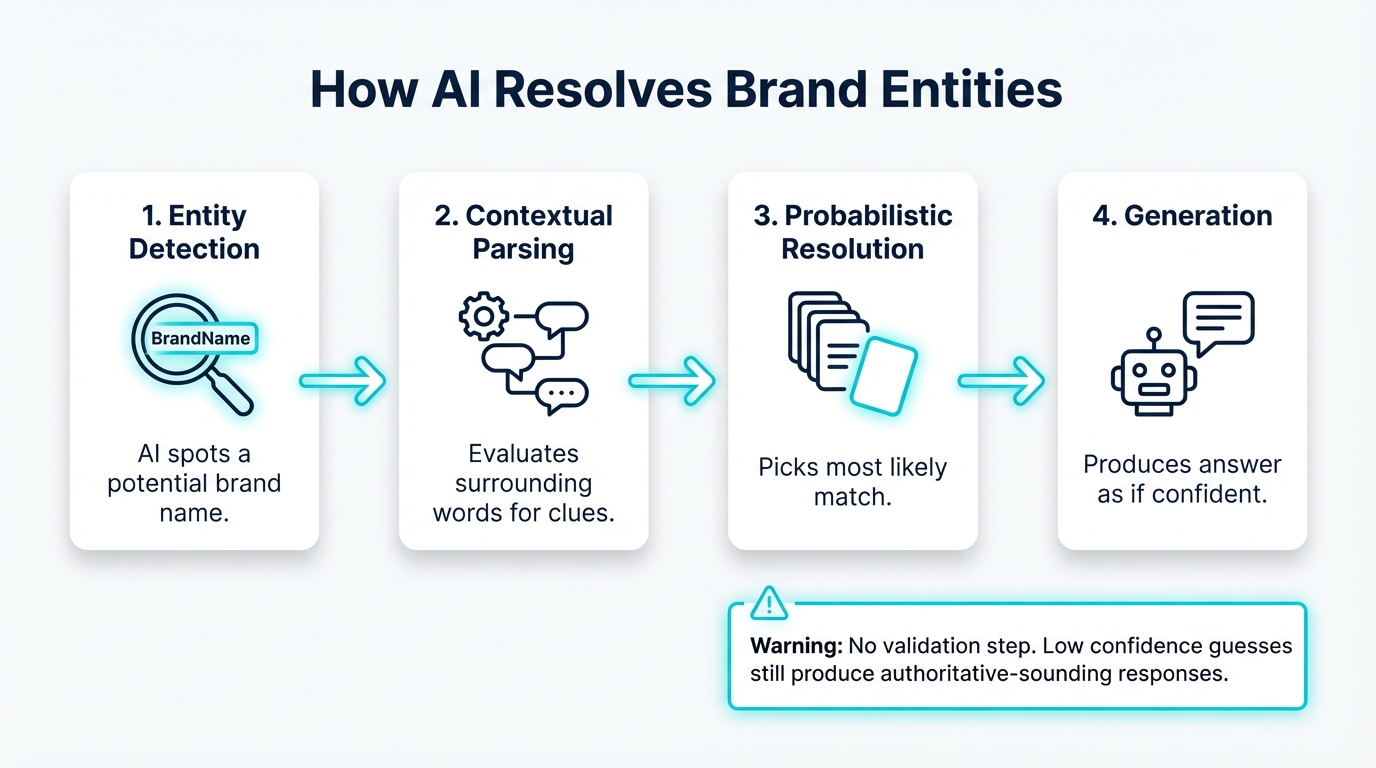
How LLMs resolve entities during inference
Implementations vary, but entity resolution often looks like this:
- Entity detection: Identifying that a phrase might refer to a named entity.
- Contextual parsing: Evaluating nearby words, user intent, and any retrieved snippets for clues.
- Probabilistic resolution: Choosing the most likely candidate entity.
- Generative completion: Producing an answer consistent with that choice.
There is not necessarily a guaranteed validation step. Low confidence choices can still produce confident sounding responses, especially when the system prioritizes helpfulness and fluent completion.
What entity disambiguation means in practice
Entity disambiguation is the process of distinguishing between multiple real world entities that share the same name or reference.
From an AI perspective, disambiguation improves when there are:
- Consistent contextual signals (same wording for what you are and what you do)
- Repeated co-occurrence patterns (your name consistently appears with your category, product type, and differentiators)
- Structural anchors (clear organization details, identifiers, and reliable relationships to other entities)
Without these, systems tend to default to surface level pattern matching. If the most common meaning of your name is not your company, you start at a disadvantage unless you provide enough anchors to shift the probability toward the correct entity in relevant contexts.
Knowledge graphs and their limits
Knowledge graphs can reduce ambiguity by representing entities with:
- Unique identifiers
- Explicit categories
- Relationships to other entities
Some AI systems may reference internal or external graph-like structures, or they may rely on web sources that themselves draw from structured entity representations. In practice, coverage, accuracy, and freshness vary across systems, and the details are often opaque.
What you can rely on is narrower: improving the public clarity and consistency of your entity information increases the chance that crawlers, indexers, and retrieval systems can associate the right facts with the right entity. It does not guarantee any single assistant will always choose correctly.
The risk of confident misrepresentation
When entity resolution fails, the outcome is rarely silence. The system typically substitutes one plausible entity for another, then generates a coherent explanation.
This can lead to:
- Incorrect associations
- Blended or fabricated attributes
- Answers to the wrong question
In generative interfaces, these errors can persist because users may not click through to verify, and the assistant may not surface uncertainty unless prompted.
The practical takeaway is not that any single score proves a root cause. It is that entity clarity tends to improve when there is more consistent, corroborated information across trusted sources and structured pages. If your brand exists primarily on your own site, systems have fewer independent references to cross-check, increasing the chance of uncertainty or confusion.
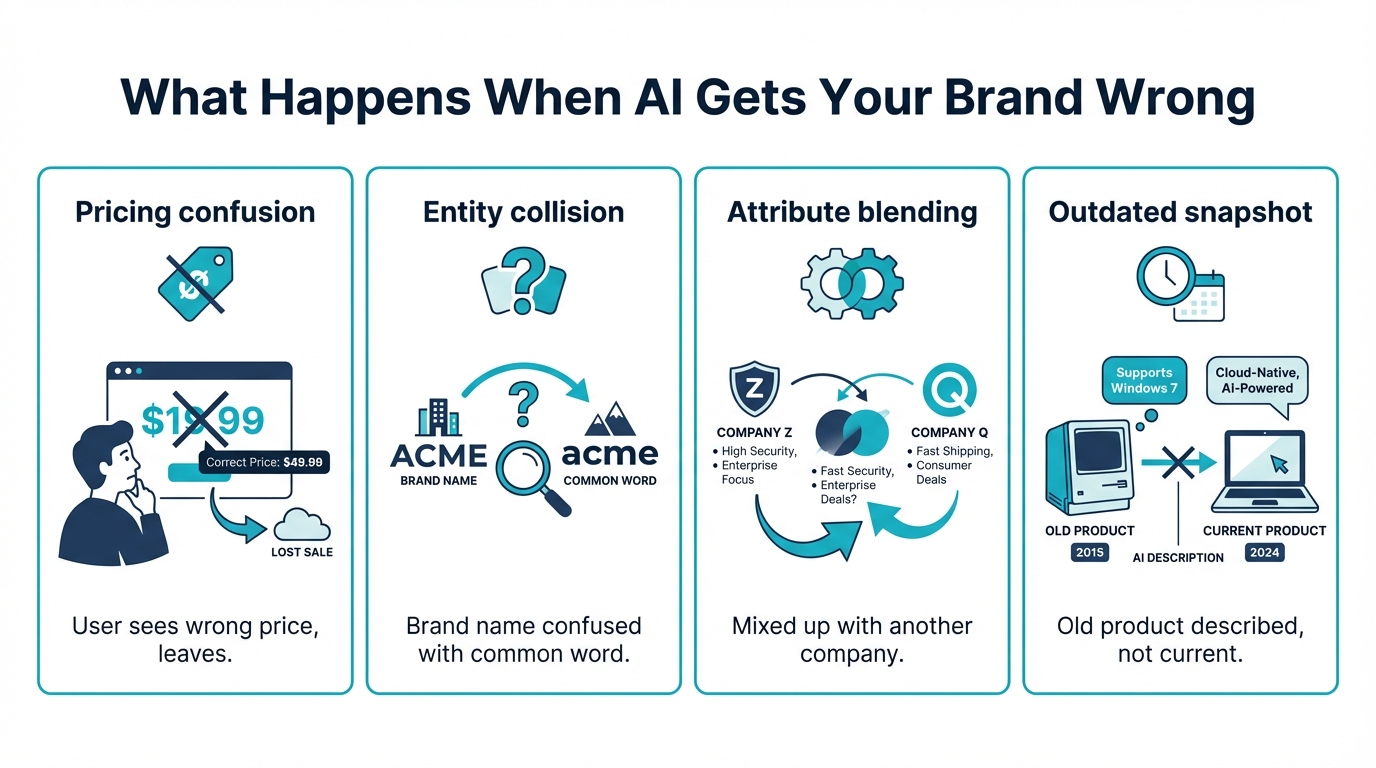
Real world impact: what happens when AI gets your brand wrong
Misidentification shows up in ordinary buying and evaluation workflows, including ones you cannot measure in analytics because no click happens.
Scenario 1, pricing confusion: A prospect asks an assistant to compare your product against a competitor. The model mixes up pricing tiers or attributes and makes you appear mispriced relative to your actual offering. The prospect does not verify on your site and moves on.
Scenario 2, entity collision: A buyer asks for the best tools for their use case. Your brand name collides with a common noun or unrelated concept, so you are omitted as a product entirely. You are effectively invisible in that interaction.
Scenario 3, attribute blending: An enterprise buyer asks about your company. The assistant blends your brand with another similarly named company in a different industry. The answer is confident but wrong: correct name, incorrect product and market.
Scenario 4, outdated snapshot: Your company pivoted recently, but the assistant relies on older sources or training data that predates the change. Users repeatedly see the old description and assume your current messaging is inconsistent.
These failures behave differently from a wrong webpage. A user can scan multiple sources in a browser, but in an assistant interface the summary may be treated as sufficient, especially under time pressure.
Root causes of brand misidentification
The mechanics can be complex, but the causes tend to cluster into a few patterns. The fix depends on which pattern applies.
Name ambiguity
Brand names that overlap with common words, other companies, or technical terms have a built-in disambiguation problem. Illustrative examples include Copper (CRM vs. metal), Notion (a product vs. a general concept), and Sage (software vs. herb vs. an adjective). If your brand name has a more common meaning, the system needs stronger anchors to choose you in the right contexts.
Thin web presence
Brands with limited coverage outside their own domain provide fewer corroborating signals. If the only information about you is on your site, many systems will have a harder time confirming identity, category, and attributes through independent references.
Inconsistent messaging across channels
If your product is described differently across your site, review platforms, partner pages, and press mentions, you create noise. Assistants may pick whichever description appears most common in the sources they see or retrieve, or they may blend multiple interpretations into a vague composite.
Data freshness and update lag
If your company launched recently or changed positioning, some systems may still reflect older descriptions. Even when retrieval is available, assistants can surface outdated pages unless you make the current description easy to find and consistently repeated across sources that are likely to be retrieved.
Category confusion
If your category is new or poorly defined, it is harder for systems to decide when you are relevant and what you should be compared against. Category clarity is part taxonomy and part repetition: the more consistently your category is described across credible sources, the easier it becomes for models and retrieval systems to place you correctly.

From search optimization to entity governance
Traditional SEO emphasizes rankings and clicks. In assistant mediated discovery, the unit of visibility is often whether your brand is correctly recognized as a distinct entity and retrieved when relevant.
Entity governance is a practical way to frame the work:
- Is the brand recognized as a distinct entity?
- Is it placed in the correct category?
- Is it retrieved and described accurately in relevant contexts?
This is not a replacement for SEO. It is an adjacent discipline focused on making your entity legible across systems that summarize, retrieve, and synthesize information.
What you can do about it
You can improve disambiguation without trying to "control" a model. The goal is to make the correct interpretation easier than the incorrect one across the ecosystem of pages, profiles, and references that assistants are likely to draw from.
1) Standardize your naming and descriptors
Pick a canonical brand name format and stick to it.
- Use the same company and product names across your homepage, About page, documentation, pricing, press kit, and blog boilerplate.
- Keep your primary category label consistent. If you must use multiple labels, define the relationship explicitly (for example, one primary category plus secondary descriptors), instead of rotating terms in different channels.
- Ensure key facts are stable and machine-readable: what you are, who you serve, where you are based if relevant, and what the product does.
This reduces confusion caused by inconsistent messaging and helps retrieval systems match repeated patterns.
2) Publish clear About and Organization information
Make it easy for crawlers and humans to find a definitive identity page:
- A dedicated About or Company page that states the legal entity name where appropriate, the brand name, and a concise description of what you do.
- Contact information and location details if applicable.
- Leadership and founding information only if you can keep it accurate and current.
Avoid writing this page like a pitch. Retrieval works better with literal statements that can be repeated elsewhere without interpretation.
3) Implement structured data, with the right expectations
Schema.org markup such as Organization, Product, and SoftwareApplication can clarify entity information for systems that crawl your site. It can help reduce ambiguity by making identifiers and relationships explicit.
Structured data is not a direct instruction that overrides model training. It is a signal that can improve how your pages are interpreted, indexed, and retrieved. Treat it as a way to reduce accidental confusion, not as a control mechanism.
Practical implementation notes:
- Use Organization markup with a stable name and URL.
- Add sameAs links to authoritative profiles (see next section).
- Keep structured data consistent with visible page content.
4) Add sameAs links and stable identifiers
Where appropriate, link your entity to corroborating profiles using sameAs in structured data and also through visible links on your site.
Useful targets include:
- Wikidata (if you have an entry)
- Google Business Profile (if applicable)
- Crunchbase (if you maintain it)
- LinkedIn company page
- GitHub organization (if relevant)
- App marketplaces or verified directories where your product is listed
The point is to reduce the number of plausible candidates for your name by tying your brand to stable identifiers.
5) Build third party corroboration you can keep accurate
Independent references help assistants and retrieval systems cross-check claims. Focus on accuracy and consistency, not volume.
Options that often function as entity anchors:
- Industry publications and interviews that describe you correctly
- Partner pages that list you with the right category and description
- Review platforms where your profile is complete and current
- Curated directories that have editorial standards
Wherever you are listed, confirm that your name, product description, and category match your canonical wording.
6) Maintain current profiles and suppress stale descriptions
Entity confusion often persists because old copy remains searchable and gets retrieved.
- Update old press releases and partner blurbs where you can.
- Ensure your press kit and boilerplate are current and easy to reuse.
- If you have multiple products, make the hierarchy explicit so assistants do not collapse them into one.
This is especially important after pivots, rebrands, or category changes.
7) Publish a definitive "What is [Brand]" page for retrieval
Create a page designed to be quoted and summarized accurately:
- A one-sentence definition at the top.
- A short section on category and use cases.
- A clear differentiation section focused on factual differences, not superlatives.
- Links to supporting documentation, pricing, and product pages.
Write with unambiguous nouns and verbs. Avoid metaphor, clever taglines, or overly compressed positioning language.
8) Monitor how assistants describe you
You cannot fix what you do not observe. Monitoring can be lightweight:
- Ask multiple assistants the same questions prospects ask (what it is, category, pricing model, competitors, integrations).
- Check whether the answer matches your current reality.
- Track recurring failure modes: wrong category, wrong competitor set, blended attributes, outdated positioning, missing mention entirely.
When you find a repeatable error, treat it like a debugging task: which source or ambiguity would cause that output, and which anchor can you strengthen to reduce that probability?

Monitoring entity disambiguation with friction AI
Platforms like friction AI track whether AI models correctly identify your brand, which can help you monitor changes over time and prioritize fixes. The value is in establishing a baseline, spotting regressions, and connecting specific misidentification patterns to the entity signals you control.
If you are evaluating monitoring tools, verify which assistants are covered, how prompts are standardized, how results are stored, and how you can trace an error back to a likely source or missing anchor.
For pricing, see the friction AI page here: https://www.frictionai.co/pricing. Last verified: July 26, 2026.
For practical steps to address this, see How to Improve Your Brand Recognition in AI.
Related guides: entity and brand recognition
The entity recognition angle: Entity SEO for AI: How Entity Theory Drives AI Visibility explores how entity theory from knowledge graphs and NLP applies to practical AI visibility.
The hidden variable: Entity Recognition: The Hidden Variable in AI Search Rankings examines why entity clarity is emerging as a ranking factor in AI search.
Practical implementation: How to Train LLMs to Understand Your Brand (Step-by-Step) provides a step-by-step guide to strengthening your brand's entity signals.
The recognition framework: The AI Brand Recognition Pyramid breaks down the three layers a brand must clear before being recommended.
Improving recognition: How to Improve Your AI Brand Recognition: A Step-by-Step Guide (2026) covers the tactical roadmap for strengthening your signal at each pyramid layer.

FAQ
Does ChatGPT have a database of brands it checks against?
Not in the way people often assume. Depending on the product and mode, it may rely on training data, retrieved web pages, connected data sources, and conversation context. There is not necessarily a deterministic brand registry lookup or a guaranteed verification step.
Can structured data force AI assistants to describe my company correctly?
Structured data can clarify entity information for systems that crawl and index your pages, and it can improve retrieval and interpretation. It is not a direct instruction that overrides what a model learned during training, and it cannot guarantee how any specific assistant will answer.
What is the fastest way to reduce entity confusion for an ambiguous brand name?
Start with what you control: consistent naming and category language, a definitive About and "What is [Brand]" page, Organization structured data with sameAs links, and accurate third-party profiles. Then monitor the most common prompts where confusion appears.
Why does the assistant sound confident when it is wrong?
Fluency is not the same as verification. Once a system selects an entity candidate, it can generate a coherent continuation consistent with that choice, even if the choice was made under uncertainty.
How often should we monitor AI answers about our brand?
Often enough to catch regressions after major changes like a pivot, rebrand, new product launch, or pricing update, and periodically to detect drift. The right cadence depends on how quickly your category and messaging change and how much you rely on assistant mediated discovery.