By Joao da Silva · April 26, 2026 · Last updated May 18, 2026
TL;DR. A real AI visibility audit is a 4-step framework, not a one-shot ChatGPT query: set up your prompts, run and track, analyze and diagnose, fix and repeat. Step 1 uses 15 starter prompts across 3 layers (entity recognition, visibility, recommendation). When we ran this on 40 SaaS brands in April 2026, only 30% cleanly passed Layer 1. Free 15-prompt template at the bottom — or run the interactive version now. Run it tonight.

▶ Watch the full walkthrough on YouTube →
When we audited 40 SaaS brands' Layer 1 visibility across two GPT generations (gpt-4o and gpt-5.2), only 12 of 40 (30%) cleanly passed all three sub-tests (full methodology + dataset). The bottleneck was not the model. The same 12 brands passed under both generations; the model upgrade did not move the number. The binding constraint was the Knowledge Graph entity, which does not change when you upgrade your LLM. Every dollar a team spends on Layer 2 and Layer 3 work is wasted while their Layer 1 entity foundation is missing, because AI cannot recommend a brand it cannot recognize.
This guide walks the 4-step audit framework you can run yourself in under an hour, the 15 starter prompts you should track quarterly, and the playbook for what to fix once you see the results.
What is an AI visibility audit?
An AI visibility audit is a structured test of how large language models (ChatGPT, Claude, Perplexity, Gemini) recognize, rank, and recommend your brand. It runs in four sequential steps: set up the right prompts, run and track responses across models, analyze the gaps, then fix and repeat. Quarterly cadence is the floor:
- Set up your prompts — 15 starter prompts across 3 diagnostic layers (entity, visibility, recommendation)
- Run and track — execute prompts 3-5x across models, capture responses
- Analyze and diagnose — read patterns; identify which layer is leaking deals
- Fix and repeat — apply layer-specific fixes; re-run quarterly
Unlike a Google rank check, AI visibility is a moving target. Search interest in "AI Visibility" grew 11.5x in the 12 months ending April 2026, and "Answer Engine Optimization" grew 5.9x (Google Trends, internal pull, Apr 2026).
How to audit brand visibility on LLMs (the short version)
Brand visibility on LLMs is the measurable share of category prompts where ChatGPT, Claude, Perplexity, or Gemini mentions your brand. Auditing it isn't a one-shot ChatGPT query — it's a 4-step framework: lock 15 starter prompts, run each 3-5 times across at least two LLMs, score per layer, then prioritize fixes by which layer is leaking deals. The full walkthrough is below.
Why a 4-step audit, not a one-shot ChatGPT query?
One ChatGPT query is a single roll of a loaded die. AI responses vary across runs, models, and phrasings. In our 40-brand audit, individual brands flipped between PASS and FAIL across gpt-4o and gpt-5.2 — Linear was unrecognized by 4o but correctly identified by 5.2. A structured 4-step audit averaged across runs produces direction; a single query produces anxiety.
The reference work here comes from Omniscient Digital. Their team analyzed 25,755 AI citations across 200 prompts and identified five universal BoFu prompt patterns that generalize across e-commerce, SaaS, services, and healthcare (Omniscient Digital, 2025). The takeaway is not that you need 200 prompts of your own. It is that the shape of a real audit is structured, repeated, and read across runs, not extracted from one screenshot.
Each step of the framework maps to a distinct discipline, and we have a dedicated deep-dive for each:
| Step | What it answers | Deep dive |
|---|---|---|
| 1. Set up your prompts | Which prompts should I run, and how do I write variants for my use case? | How to write AI visibility prompts → |
| 2. Run and track | How do I run these across ChatGPT, Claude, Perplexity, and Gemini at scale? | Track brand mentions in ChatGPT, Claude & Perplexity → |
| 3. Analyze and diagnose | What do failure modes look like, and how do I read the pattern? | Why AI ignores your brand: 11 failure modes → |
| 4. Fix and repeat | Where do I find new prompts to add as my buyers evolve? | Find buyer questions for AI prompts → |
Want to see the framework applied at scale? We ran it across 40 real SaaS brands and published the 40-brand AI visibility audit case study with full methodology, dataset, and findings.
Step 1 — Set up your prompts (the prompt audit foundation)
Step 1 is what you'll run — picking prompts that map to real buyer queries, not marketing-voice phrasings. The 15-prompt universal starter set covers 3 diagnostic layers (entity recognition, visibility, recommendation), with 5 prompts per layer. Each prompt tests a distinct failure mode in how AI sees your brand.

The framework draws on two pieces of public research. Citation Labs identified four properties that make a BoFu prompt worth tracking: contrastive reasoning ("better," "worth it"), offer-anchoring (a specific brand named), category anchoring, and constraint clauses (Citation Labs, 2025). Omniscient's five universal BoFu patterns slot into the same Layer 3 set: pricing, comparison, social proof, fit, and verdict. Both frameworks are reflected in the prompts below.
What is an LLM prompt audit?
An LLM prompt audit is the prompt-design and execution portion of an AI visibility audit — Step 1 of the 4-step framework, where you lock the 15 starter prompts (5 per diagnostic layer) and any use-case variants before running them. The prompt set decides what you can diagnose; everything downstream (runs, analysis, fixes) inherits from this choice.
The 15 universal starter prompts
| # | Layer | Prompt |
|---|---|---|
| 1.1 | Entity | Who is [your brand]? |
| 1.2 | Entity | What does [your brand] do? |
| 1.3 | Entity | Who founded [your brand]? |
| 1.4 | Entity | What is [your brand] known for? |
| 1.5 | Entity | Tell me about [your brand]'s product. |
| 2.1 | Visibility | What are the best [category] tools for [ICP]? |
| 2.2 | Visibility | Which [category] software is best for [use case]? |
| 2.3 | Visibility | What's the best [category] for [tight niche]? |
| 2.4 | Visibility | What [category] platforms are most popular right now? |
| 2.5 | Visibility | What tools help with [buyer's problem]? |
| 3.1 | Recommendation | How much does [your brand] cost? |
| 3.2 | Recommendation | How does [your brand] compare to [competitor]? |
| 3.3 | Recommendation | What do users say about [your brand]? |
| 3.4 | Recommendation | Is [your brand] good for [my use case]? |
| 3.5 | Recommendation | Is [your brand] worth it? |
Run each prompt three to five times, average the results, then read the patterns. Three runs is the minimum that surfaces variance; five gives you confidence on the top entry. Single-run readings are how marketers convince themselves they are winning when they are not.
Layer 1: Entity Recognition — does AI know your brand exists?
Layer 1 is the foundation. It tests whether AI has your brand in its model at all, whether the description is accurate, and whether the founder, founding date, and product knowledge are right. Fail it, and Layers 2 and 3 are moot. In our 40-brand Layer 1 audit (April 2026, run on both gpt-4o and gpt-5.2), 28 of 40 brands (70%) had at least one Layer 1 failure (full audit dataset). The most common failures were entity foundation missing (no Knowledge Graph entry) and a pattern called CONFUSED_IDENTITY: the LLM picking the wrong company with the same name and describing it confidently.
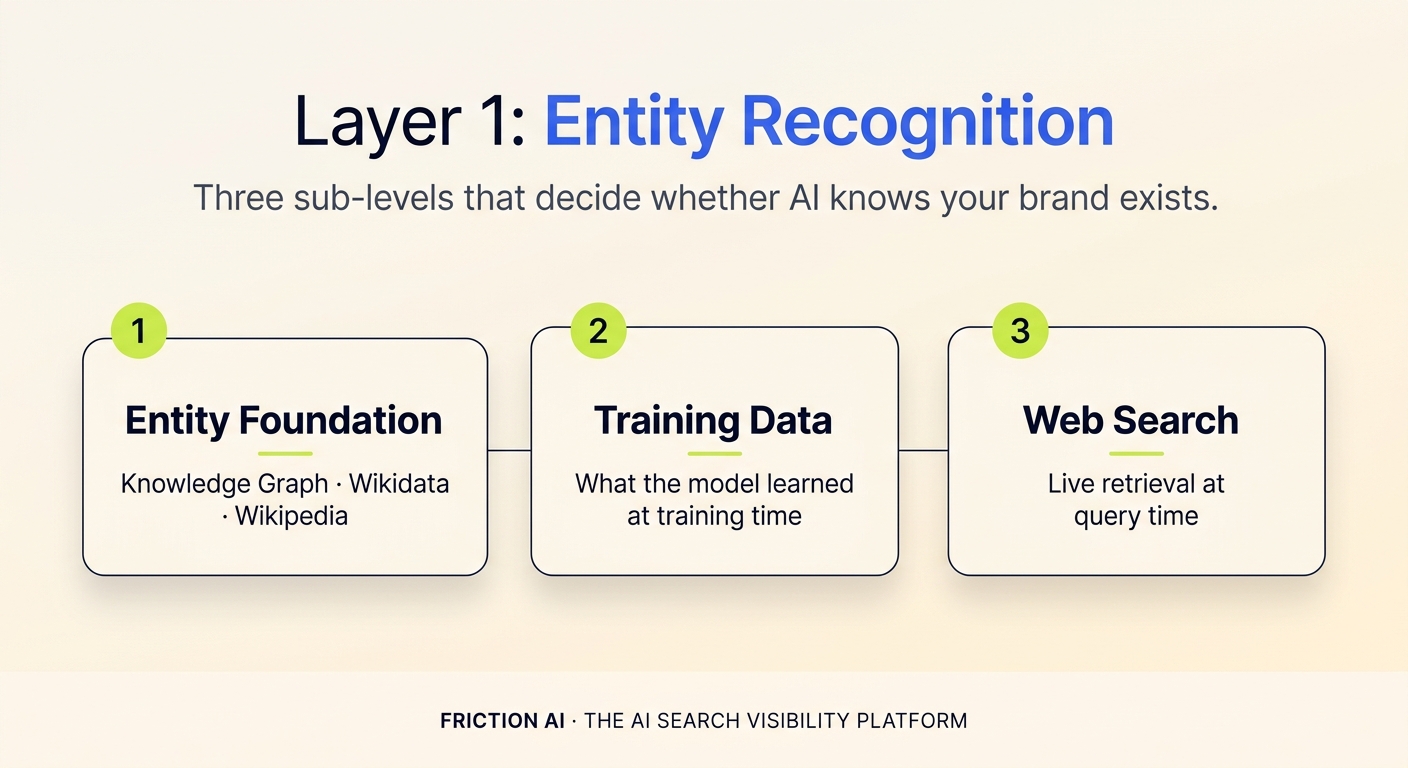
Layer 1 actually splits into three sub-levels, each with a different fix lever:
- Entity foundation is structural recognition. Does AI have you in its knowledge graph? Failure here means the fix is schema markup, Wikipedia presence, and structured data on your site.
- Training data is what AI learned historically, before its training cutoff. You cannot retroactively change what current models know, but you can influence future training rounds by publishing high-authority content now (12 to 24 month horizons).
- Web search / live retrieval is what AI fetches when search is enabled (ChatGPT Search, Perplexity, Claude with web). Failure here means a freshness gap: your indexable web footprint is thin or stale.
The five Layer 1 prompts each test a different dimension. 1.1 (Who is...) tests misidentification. 1.2 (What does...do) measures whether AI's first-sentence description matches your positioning. 1.3 (Who founded...) surfaces hallucinated founders. 1.4 (What is...known for) is the highest-leverage Layer 1 prompt — if "known for X" doesn't match what you're selling, third-party content is shaping the narrative without you. 1.5 (Tell me about...product) reveals what AI omits — missing recent features signal stale training data.
Layer 2: Visibility — where do you sit on the leaderboard?
Layer 2 is competitive intelligence in disguise. Every "best [category] for [ICP]" prompt reveals the leaderboard AI sees for that category, problem, or niche. The diagnostic value is not "do I show up?" (the passive question), it is "who does AI consider strongest in this space, and where do I rank against them?" (the active question). The active framing is what makes Layer 2 worth running quarterly.

Each Layer 2 prompt reveals a different leaderboard. These are not five versions of the same ranking — they are five competitive landscapes running in parallel:
- 2.1 (Best [category] for [ICP]) tests the head term plus your buyer segment.
- 2.2 (Best for [use case]) tests use-case specificity. A brand can win the head term and still lose use-case-specific queries.
- 2.3 (Best for [tight niche]) is where smaller brands often win. Niche dominance shows up even when the brand is invisible at the head term.
- 2.4 (Most popular right now) tests temporal bias. AI defaults to incumbents.
- 2.5 (Tools that help with [buyer's problem]) tests problem-led discovery.
A brand can be #1 on the head term and invisible on the problem-led version. The pattern of where you DO rank versus where you do not tells you which content gap to close first. AI sources from Reddit, "best of" listicles, comparison sites, and podcast transcripts in addition to traditional SEO surfaces, and that mix can surface different brands than Google does.
Layer 3: Recommendation — does AI pick you, and hide concerns?
Layer 3 is the selection filter — the layer where deals are won or lost in real time. By the time a buyer is at Layer 3, they already know you exist and they've surfaced you in their research. AI is the last filter before they commit. If it hedges, hallucinates pricing, or describes a competitor more favorably, you lose deals you almost won. And you never find out why.
Layer 3 splits into two distinct lenses, each diagnosing a different AI behavior:
Lens 1 is the Favorite Test. When forced to compare you against a named competitor, what does AI do? Tested by 3.2 and 3.5.
Lens 2 is the Concerns Test. When asked about you in isolation, what reservations does AI quietly surface? Tested by 3.1, 3.3, 3.4, and 3.5.
A brand can win Lens 1 (AI picks you head-to-head) and still lose Lens 2 because AI surfaces outdated complaints every time it describes you. A Layer 3 audit should produce two scores, not one.
| # | Prompt | Lens | Diagnoses |
|---|---|---|---|
| 3.1 | How much does [brand] cost? | Concerns | Pricing accuracy, hidden cost objections |
| 3.2 | How does [brand] compare to [competitor]? | Favorite | Head-to-head competitive framing |
| 3.3 | What do users say about [brand]? | Concerns | Outdated negative reviews surfacing |
| 3.4 | Is [brand] good for [use case]? | Concerns | Fit hedging vs. clean commitment |
| 3.5 | Is [brand] worth it? | Both | Verdict commitment plus surfaced caveats |
When to write your own prompt variants
The 15 above are the universal starter set — they work for any SaaS brand. If your category has unique buyer language, multi-product complexity, or industry-specific intent, you'll want to write 8-12 use-case variants on top: sentiment-specific, competitor-specific, ICP-specific. We covered the deep-dive workflow in how to write AI visibility prompts.
Step 2 — Run and track
Step 2 is execution — running each prompt 3-5 times across ChatGPT, Claude, and Perplexity, then capturing the responses for scoring. Whether you run by hand (about 45 minutes per brand per round) or use tooling, the core workflow follows the same five-step sequence below.
- Plug your
[brand],[category],[ICP],[competitor]placeholders into the 15 prompts - Run each prompt 3-5 times in your model of choice
- Run the full set in at least 2 platforms (start with ChatGPT, then Claude or Perplexity)
- Capture each response — copy-paste into a doc, take a screenshot, or use an automated tracker
- Score each prompt: pass, fail, or partial
The cross-model divergence is where Step 2 earns its keep. The same 15 prompts in ChatGPT, Claude, Perplexity, and Gemini can produce different leaderboards because each model has a different training mix and different live-retrieval logic. Cross-model agreement is anecdotally low; in our own testing, the top-brand pick diverges substantially across ChatGPT, Perplexity, and Claude. A rigorous cross-model study with published n is on our v3 audit backlog.
Doing this at scale
Running 15 prompts × 3-5 runs × 4 platforms quarterly = 180-300 manual queries per audit cycle. Most teams burn out at run 2. We covered the workflow for tracking this continuously across platforms in how to track brand mentions in ChatGPT, Claude & Perplexity, including the manual workflow, the failure modes of common spreadsheet approaches, and the automated alternatives.
Step 3 — Analyze and diagnose
Step 3 is reading the pattern across runs. The audit produces three signals per brand: per-layer pass rate (how often AI recognizes / ranks / recommends you), per-prompt failure mode (the specific pattern that's breaking), and per-platform divergence (where ChatGPT, Claude, and Perplexity disagree). The combination tells you which layer is leaking deals.
What our 40-brand audit found
Three findings from running the Step 1 + Step 2 workflow on 40 SaaS brands across two GPT generations:
1. The Knowledge Graph is the binding constraint, and it does not move with model upgrades. The same 12 brands cleanly passed all three sub-tests on both gpt-4o and gpt-5.2:
- HubSpot, Pipedrive (CRM)
- Asana, Monday.com, Notion, ClickUp (project management)
- Mixpanel, Amplitude, Heap, Hotjar (product analytics)
- Copy.ai, Writesonic (AI content)
All 12 have high-confidence Knowledge Graph entries (resultScore over 100). The model upgrade improved recall, but the Layer 1 strict pass count was identical. For a brand pursuing AI visibility, fixing the Knowledge Graph entity is the highest-leverage Layer 1 action; it gates everything downstream.
2. As LLMs get better at recall, the failure mode shifts from "never heard of you" to "wrong company with your name." On gpt-4o, NOT_RECOGNIZED ("I'm not familiar with...") accounted for 65% of Layer 1 failures. On gpt-5.2, that dropped to 52%, while CONFUSED_IDENTITY rose to nearly half of all failures (40-brand audit, April 2026). As model recall improves, generic brand naming becomes the dominant failure mode. This is the bad kind of progress: a confidently wrong answer is more dangerous than an honest "I don't know."
3. Generic-named brands stay broken across model upgrades. Four brands in the cohort (Bud, Forge, Roark, Trim) fail CONFUSED_IDENTITY on both training-data and web-search tests, on both gpt-4o and gpt-5.2. The model picks Howard Roark, Atlassian Forge, Trim County in Ireland. Even a Series A startup with strong product traction stays invisible in AI when its name collides with a famous fictional character or an established corporate trademark. Generic naming is a Layer 1 visibility issue that no model upgrade is likely to fix.
Common failure modes to look for
Beyond the 3 macro findings above, individual posts surface specific failure patterns: pricing hallucination, comparison ordering bias, outdated negative reviews, the hedge ("It depends..."), CONFUSED_IDENTITY, missing recent features. We cataloged the 11 most common AI visibility failure modes — read this before your first audit so you know what to look for in the response patterns.
Methodology validated at scale
If you want the full dataset and methodology behind the findings above — sample frame, scoring rubric, sub-test definitions, raw response logs, and limitations — see the 40-brand AI visibility audit case study. It's the proof-of-method for everything in this guide.
Step 4 — Fix and repeat
Step 4 is sequencing your fixes in the right order. The diagnostic value of the audit collapses to zero if you fix the wrong layer first: Reddit content campaigns are wasted while AI doesn't yet recognize your brand, and PR investments take 60-90 days to register in AI's training and retrieval surfaces.
Prioritization
Fix Layer 1 first, even if Layers 2 and 3 look worse on paper. The reason is sequencing. Layer 1 fixes (Wikipedia, schema, founder presence) compound forward into Layer 2 and 3 visibility, while Layer 2 and 3 fixes do nothing for Layer 1. Spending on a Reddit content campaign before AI knows your brand exists is a waste.
Once Layer 1 is clean, prioritize Layer 2 work for your three weakest prompts (the ones where you are invisible), not your three strongest. The marginal return on closing a visibility gap is higher than the marginal return on improving an existing rank. Save Layer 3 fixes for last because they are the slowest to compound; PR cycles, fresh reviews, and updated case studies show up in AI's answers on 60 to 90 day lags.
The second-order point on Layer 3 is that fixing it almost always means more PR, not more on-page SEO. Off-site authority compounds slowly, and the brand reputation AI sees lags reality by 1 to 3 quarters. Search Engine Land made this case directly: PR is becoming more essential for AI search visibility than traditional optimization because AI reads the entire web and weights publication authority.
How often should you re-run the audit?
Quarterly is the minimum. Monthly is right if your category is hot or your competitive landscape is shifting fast. AI's answers move every few weeks as content gets indexed and competitors enter, so a one-time audit is data, but a recurring audit is direction. The pattern of which prompts shift over time tells you whether your investments are working. If Layer 2 prompts improve quarter over quarter while Layer 3 stays flat, your off-site authority work is paying off, but your validation surface still has gaps.
You should also run the audit across multiple models. The category itself is maturing fast enough that tooling has shifted. Peec AI raised $21M Series A in November 2025 to build out an Actions feature. Profound is building enterprise multi-model tracking. Semrush AI Visibility Toolkit and Ahrefs Custom Prompt Tracking shipped to existing customer bases in the same window. Re-run after every major model update (GPT, Claude, or Gemini); earlier results may not transfer.
Finding new prompts as your buyers evolve
The 15 starter prompts are universal but static. Your buyers' questions evolve quarterly: new objections surface in sales calls, new comparison brands enter the market, new use cases emerge in support tickets. We laid out the playbook for mining real buyer language from Reddit, sales calls, and support tickets in find buyer questions for AI prompts. Run this every 60-90 days to keep your audit current.
The free 15-prompt template (copy-paste version)
Two ways to run this: copy the block below into a doc and fill in [brand], [category], [ICP], [use case], [tight niche], [buyer's problem], [competitor] yourself, or grab the free interactive 15-prompt tool (no signup) to drop into ChatGPT, Claude, or Perplexity. Then run each prompt 3 to 5 times in your model of choice and average the readings. The whole audit fits in about 45-60 minutes for a single brand.
Layer 1 — Entity Recognition (run with web search OFF first, then ON)
1.1 Who is [your brand]?
1.2 What does [your brand] do?
1.3 Who founded [your brand]?
1.4 What is [your brand] known for?
1.5 Tell me about [your brand]'s product.
Layer 2 — Visibility (no brand name in any prompt)
2.1 What are the best [category] tools for [ICP]?
2.2 Which [category] software is best for [use case]?
2.3 What's the best [category] for [tight niche]?
2.4 What [category] platforms are most popular right now?
2.5 What tools help with [buyer's problem]?
Layer 3 — Recommendation (run head-to-head against your top 3 competitors)
3.1 How much does [your brand] cost?
3.2 How does [your brand] compare to [competitor]?
3.3 What do users say about [your brand]?
3.4 Is [your brand] good for [my use case]?
3.5 Is [your brand] worth it?
Score each prompt simply: pass, fail, or partial. Aggregate by layer. The pattern is the audit. If you would rather automate the run across ChatGPT, Claude, and Perplexity in parallel and track scores quarterly without doing it by hand, that is the problem friction AI was built to solve. The manual workflow above is genuinely enough to get a first read.
Frequently Asked Questions
Common questions brand teams ask after running their first AI visibility audit, with answers grounded in the 4-step framework, the 40-brand cohort study, and pattern data across thousands of LLM runs. Skim for what matches the gaps you're seeing in your own audit results.
How do I audit brand visibility on LLMs?
Brand visibility on LLMs is the share of category prompts where ChatGPT, Claude, Perplexity, or Gemini mentions your brand. To audit it, run a 4-step framework: lock 15 starter prompts across 3 diagnostic layers (entity recognition, visibility, recommendation), execute each prompt 3-5 times across at least two LLMs, score per layer, then prioritize fixes by which layer is leaking the most deals.
What is an LLM prompt audit?
An LLM prompt audit is the prompt-design and execution portion of an AI visibility audit. You lock a set of 15 universal starter prompts plus optional use-case variants, run each one 3-5 times across ChatGPT, Claude, Perplexity, and Gemini, then score responses by diagnostic layer. The prompt set decides what you can diagnose — everything downstream (runs, analysis, fixes) inherits from this choice.
How do I do an AI visibility audit step by step?
Four sequential steps. Step 1: set up your prompts (use the 15 starter prompts or write 8-12 use-case variants). Step 2: run and track (execute each prompt 3-5 times in ChatGPT, Claude, Perplexity, Gemini, log mentions per platform). Step 3: analyze and diagnose (read per-layer pass rates, identify which layer is leaking deals). Step 4: fix and repeat (apply layer-specific fixes — schema, third-party PR, comparison content — re-run quarterly).
How do I run an AI visibility audit for a B2B SaaS company?
Use the 15-prompt framework with B2B SaaS placeholders: [brand] = your tool, [category] = your software vertical (CRM, project management, analytics), [ICP] = your buyer segment (Series A founders, mid-market RevOps, enterprise CTOs). Run across ChatGPT, Gemini, and Perplexity (B2B buyers use all three: ChatGPT for solo research, Gemini for Google ecosystem, Perplexity for sourced citations). Add 2-3 vertical-specific prompts (integration questions, pricing tiers, free-trial fit).
What's the difference between AI visibility, AEO, and GEO?
AI visibility is the broad term for how brands appear in AI answers. Answer Engine Optimization (AEO) is the optimization discipline that improves citation in answer engines like ChatGPT, Perplexity, and Google AI Overviews. Generative Engine Optimization (GEO) is the same thing under a different name, used more often in academic and SEO-tool contexts. All three solve for the same outcome: AI mentions your brand when buyers ask.
How long does fixing Layer 1 entity recognition take?
Structural fixes (schema markup, Wikipedia, knowledge graph submissions) can show up in AI's web-search answers within days to weeks. Training-data fixes (what AI knows without web search) take 12 to 24 months because they only flow into the next training cycle. Web-search fixes (fresh content, recent press) appear fastest. Most teams see meaningful Layer 1 movement within a quarter if they prioritize the structural and live-retrieval levers together.
Should I run this audit on ChatGPT, Claude, or Perplexity first?
Start with whichever model your buyers use most, and that is usually ChatGPT for B2B SaaS audiences. Once you have a baseline, run the same 15 prompts in Claude and Perplexity. Cross-model variance is the second-most useful signal in the audit, because a leaderboard that agrees across all three is a much stronger signal of true rank than one that only shows up in ChatGPT.
Is the 4-step audit enough for enterprise brands?
The 4-step framework with 15 starter prompts is the universal core. Enterprise brands with multiple products, multiple ICPs, or multiple geographies should run a separate audit per product or segment, not stack everything into one. Add 1 to 2 vertical-specific prompts on top (free trial questions for SaaS, shipping questions for e-commerce, insurance questions for healthcare). The framework holds; the inputs change.
Can I run this audit for free?
Yes. The manual workflow above costs nothing besides your time and a ChatGPT, Claude, and Perplexity account. Each platform has a free tier that supports the 15 prompts. Tooling automates the run across models, tracks results quarterly, and flags shifts, which matters at scale; it is not required to get a first read.
How does this differ from traditional SEO ranking checks?
Traditional rank tracking watches one thing: your position on Google for a keyword. The 4-step AI visibility audit watches three: whether you exist in the model, where you rank in AI's answer mix, and whether AI commits to recommend you. AI sources from Reddit, podcasts, and comparison sites in addition to traditional SEO surfaces, so a brand can rank #1 on Google and be invisible in ChatGPT (and the reverse). Both audits are useful; they measure different things.
What if my brand has multiple products or ICPs?
Run the audit per product, not per parent brand. ChatGPT might know HubSpot the company perfectly and be vague on HubSpot Marketing Hub specifically. Same for multi-ICP brands: if you sell to startups and enterprise, run separate audits because buyer language and AI's recommendation patterns shift completely between segments. The 15 prompts stay the same; the [brand], [category], and [ICP] inputs change per audit.
Methodology footnote. Layer 1 statistics in this post come from a 40-brand cohort audit conducted by friction AI in April 2026. Full methodology, dataset, raw response logs, and limitations live in the case study writeup. Quick version:
- Sample (n=40): stratified across 20 G2 category leaders (CRM, project management, product analytics, AI content) and 20 Y Combinator W24/W25 B2B SaaS startups. The "average SaaS brand" is neither; the headline 30% pass rate is read against this specific sample frame, not the universe of all SaaS.
- Three sub-tests per brand: entity foundation via the Google Knowledge Graph Search API, training-data recognition via OpenAI gpt-4o and gpt-5.2 (no tools), web-search recognition via the same models with
web_searchtool use forced. - Prompt scope: the LLM tests used a single brand-anchored prompt ("Who is [brand]?") corresponding to prompt 1.1 of the 15-prompt framework. Prompts 1.2 through 1.5 were not run in this cohort.
- Scoring: single-rater, no inter-rater reliability check. 40 brands is directional rather than statistically powered for sub-segment claims.
- Out of scope: Layer 2 (visibility) and Layer 3 (recommendation) were not tested. Other LLMs (Anthropic Claude, Google Gemini) were not tested.
Run this audit on your own brand
Want this 4-step audit running across ChatGPT, Claude, Perplexity, and Gemini on a continuous schedule — without doing the spreadsheet by hand?
▶ Start your free trial of friction AI →
Or grab the free 15-prompt starter pack → and run the manual workflow tonight.
About the author. Joao da Silva is co-founder of friction AI alongside Camilla Wirth. friction AI tracks brand visibility across ChatGPT, Claude, Perplexity, and Gemini for SaaS and DTC brands. Joao writes about AI search, entity recognition, and the operational side of getting recommended by LLMs. Connect with him on LinkedIn.